A couple of years ago we decided we wanted to make sure that we were responding promptly to issues that users created on our GitHub repos. In particular, a 3-business day SLA was what we thought would be appropriate. Making sure that we did that day after day could be a bit tedious, so I thought it made sense to automate it.
We had a vast trove of GitHub data in our Kusto data warehouse for every repository owned by Microsoft. It was possible to run Kusto queries and send e-mail using our low-code/no-code Power Apps platform, so I spent some time writing the queries and getting this all set up, and it worked great.
Unfortunately, a few months later, the team that maintained all the GitHub data in Kusto decided to change the schema and migrate it all over to new tables. And even worse for my use case, they weren’t going to migrate everything (I think it was a lot of data and not a lot of people were using it the way I was). This meant a key query I needed, which got the members of the team responsible for maintaining a repo (including past members who may have moved on, perhaps even leaving Microsoft), would no longer work. I had other things keeping me busy, and decided not to fix this system. But I missed the insights it gave.
More recently, we started accumulating a lot of old issues in Pylance, and because it has been a rapidly evolving product, the cost of investigating these old issues was non-trivial but not always worthwhile. So I thought it might be time to bring back my reports, but to do it in a way that was easier for others to leverage. In particular, I didn’t want to take a dependency on the data warehouse.
I now have this working, and in this post will describe how I am doing it, and show how you can leverage this yourself if you find it useful. Let me start by sharing a typical report (note: “OP” stands for “original poster”; I essentially distinguish between the original poster, my team members, and everyone else (“third party”)):
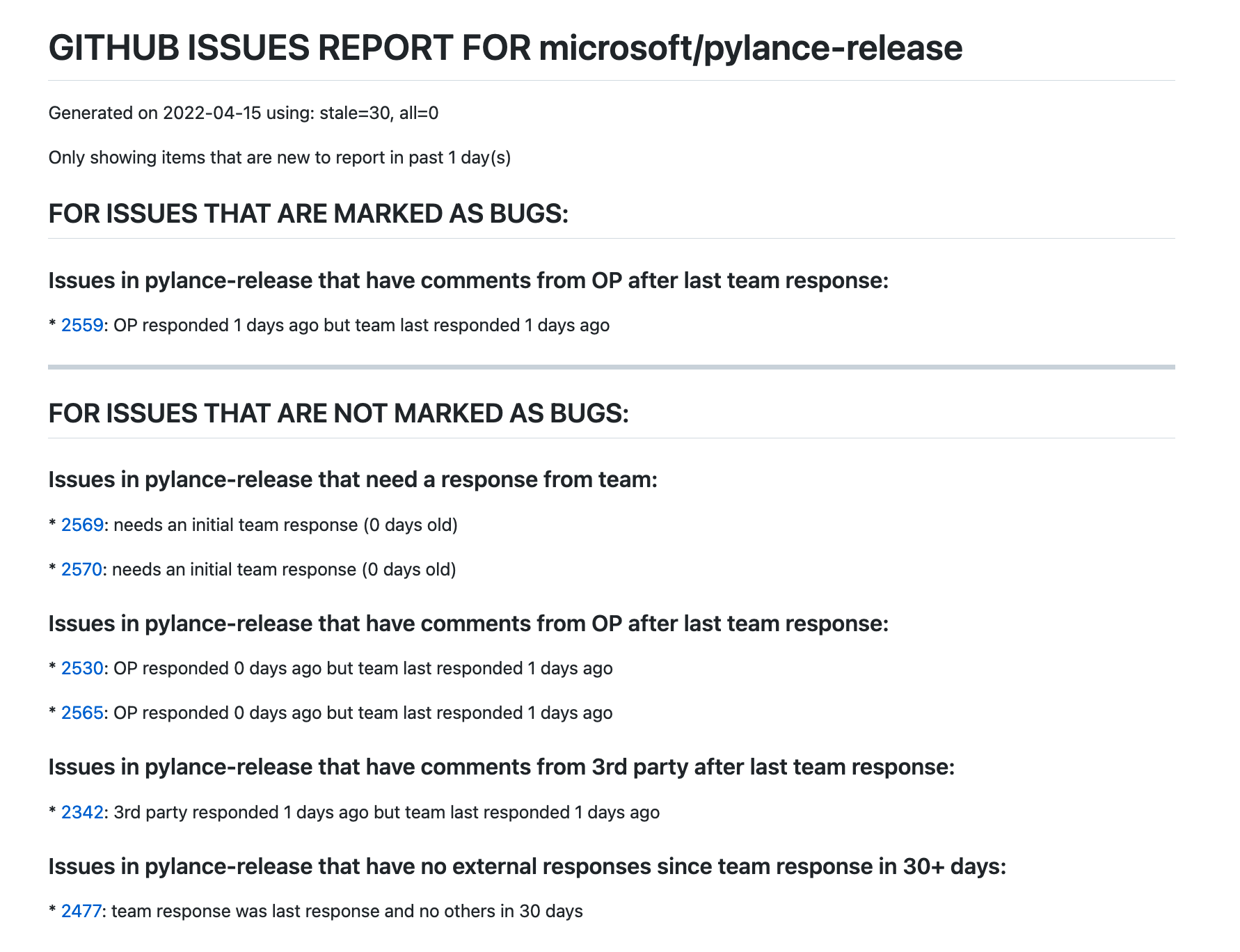
You’ll notice that I first distinguish between issues marked as bugs and those not; I think this is a useful separation. There are then several further subsections:
- Issues that need a response from team:
- Issues that have comments from OP after last team response
- Issues that have comments from 3rd party after last team response
- Issues that have no external responses since team response in 30+ days (the actual number of days is configureable):
There’s also two variants of these reports: full reports (that get run once a week) and daily incremental reports (showing only those issues that have changed status in the past day).
These reports get generated automatically by GitHub actions and committed to a repo; I name them with the day of the week so I have a 7-day rolling window effectively. The repo where this happens is here
There are several components to the system:
- there is a GitHub workflow for each report, that runs on a schedule. This needs to be configured withe the repo, the access token, and the type of report, as well as an optional batch size which can be useful in rare cases where issues have many events that cause the query responses to be too large;
- the workflows in turn each make use of a GitHub action, which is still largely specific to my use case, but adds additional settings that are common across all my reports; for example, it specifies all the GitHub user names of people in my team, and adds the
microsoft/organizational part of the repository path. This action is mostly just me following DRY (don’t repeat yourself) principles; - that GitHub action in turn makes use of a generic GitHub action, which is what you would make use of if you customized this yourself; this action requires a full set of input parameters and makes very few assumptions about the inputs beyond having some default values;
- that action then leverages a utility
ghreportwritten in Python that queries GitHub APIs for the repo specified at the start and using the initially passed-in access token, and generates the reports in Markdown format (it supports HTML format too, in which case it can include a chart of bug rates over time, but for the purposes of having automated reports committed to a GitHub repo that are easy to read, Markdown makes more sense).
We’ll go through each of these in turn. I should note that in my day to day job I am a manager of managers and don’t normally get to write GitHub actions; this was my first time, so there may be things I am doing inefficiently or non-idiomatically. I welcome feedback.
The Python Utility ghreport
Below I’ll dive into a few pieces of the code.
Get the Team Members
In the reports, we want to distinguish between team members and non-members. One way to do this is to find who can push to the repo, or administer the repo. This is not public knowledge (i.e. you can’t see this for repos you don’t own), so does require you to have elevated permissions.
In the end, for my reports, I don’t use this; it uses up my API quota, uses the REST APIs so is slow, and doesn’t include people who have left the team. I added a way to override or augment the users that this function retrieves, and I leverage that. But if you don’t know who is in the team, this is a good way to get an initial list.
def get_members(owner:str, repo:str, token:str) -> set:
"""
Get the team members for a repo that have push or admin rights.
This is not public so if you are not in such a team (probably with admin rights) this will fail.
I haven't found a good way to use the GraphQL API for this so still uses REST API.
"""
g = Github(token)
ghrepo = g.get_repo(f'{owner}/{repo}')
rtn = set()
try:
for team in ghrepo.get_teams():
if team.permission not in ["push", "admin"]:
continue
try:
for member in team.get_members():
rtn.add(member.login)
except Exception:
pass
except Exception:
print(f"Couldn't get teams for repo {owner}/{repo}")
return rtn
Getting Open Issues and their Events
The key piece to getting the data is the GraphQL query. An earlier version of my code used the REST API, but it is very inefficient and requires many calls to get all the necessary data; with the API rate limiting that happens it can take hours to get all the data necessary. In contrast, the GraphQL approach takes only a few queries and can be done in minutes if not seconds.
I’m not going to explain how to use GraphQL here; there are plenty of references for that. Suffice it to say that in our query, we want to get all the open issues for a repo, and for each issue we want the number, title, timestamp when created, original author, and the subsequent timeline events if they are label, unlabel, or comment events. We need the label events to distinguish bugs from other issues, and for the comment events we want to know who commented and when. We limit to 100 timeline events which should be enough for most issues, while we get pagination continuation for the issues themselves in case they can’t be retrieved in a single call. The key subset of the query is :
repository(owner: $owner, name: $repo) {
issues(states: [OPEN], first: $chunk, after: $cursor) {
totalCount
pageInfo {
endCursor
hasNextPage
}
nodes {
number
title
createdAt
closedAt
author {
login
}
timelineItems(
first: 100
itemTypes: [LABELED_EVENT, UNLABELED_EVENT, ISSUE_COMMENT])
{
...
}
}
}
}
(We’re also getting timestamp when closed; that is historical as an earlier version didn’t filter the results to only open issues).
In order to run this query, I use the Gidgethub Python package (named after Brett Cannon’s cat Gidget). Having fetched the data from GitHub, I turn it into a list of dataclass instances:
@dataclass
class Event:
when: datetime
actor: str
event: str
arg: str
@dataclass
class Issue:
number: int
title: str
created_by: str
created_at: datetime
closed_at: datetime
first_team_response_at: datetime # first comment by team
last_team_response_at: datetime # last comment by team
last_op_response_at: datetime # last comment by OP
last_response_at: datetime # last comment by anyone
events: List[Event]
is_bug: bool
Generating the reports once we have this data is fairly straightforward.
The Generic GitHub Action
# yaml-language-server: $schema=https://json.schemastore.org/github-action.json
name: "github-issue-reporter"
description: "Generates reports (typically daily) of potentially stale issues or issues that need attention."
inputs:
repository:
description: "The GitHub repository to generate the report for."
required: false
default: $GITHUB_REPOSITORY
githubToken:
description: "The Github token or PAT token (preferred) for API access."
required: true
reportPath:
description: "Path of report folder"
required: false
default: "reports"
reportNameTemplate:
description: "File name template for reports. Can use metacharacters understood by Python strftime."
required: false
default: "report-%a.md"
team:
description: "Comma-separated list of team members. Start with + if this is comprehensive."
required: false
default: ''
days:
description: "Time window (in days) for reports. Used to determine what items are new since last report."
required: false
default: '1'
count:
description: "Batch size for Github API call; reduce if action is timing out during API calls."
required: false
default: '25'
all:
description: "Whether to show all items or only those that are new (based on time window)."
required: false
default: false
branch:
description: "The branch to use for pushing the reports to."
required: false
default: 'main'
runs:
using: "composite"
steps:
- name: Check out code
uses: actions/checkout@v2
with:
persist-credentials: false # otherwise, the token used is the GITHUB_TOKEN, instead of the passed-in token.
ref: ${{ inputs.branch }}
fetch-depth: 0 # otherwise, there would be errors pushing refs to the destination repository.
- name: Setup Python
uses: actions/setup-python@v2
with:
python-version: "3.9"
- name: Cache pip
uses: actions/cache@v2
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
restore-keys: |
${{ runner.os }}-pip-
- name: Install reporter
run:
python -m pip install ghreport
shell: bash
- name: Ensure directory exists
run:
mkdir -p ${{ inputs.reportPath }}
shell: bash
- name: Generate full report
if: inputs.all == 'true'
run:
ghreport -a -n ${{ inputs.count }} -o ${{ inputs.reportPath }}/${{ inputs.reportNameTemplate }} -t ${{ inputs.team }} -d ${{ inputs.days }} ${{ inputs.repository }} ${{ inputs.githubToken }}
shell: bash
- name: Generate limited report
if: inputs.all != 'true'
run:
ghreport -n ${{ inputs.count }} -o ${{ inputs.reportPath }}/${{ inputs.reportNameTemplate }} -t ${{ inputs.team }} -d ${{ inputs.days }} ${{ inputs.repository }} ${{ inputs.githubToken }}
shell: bash
- name: Commit report
id: commit
run: |
git config --local user.email "action@github.com"
git config --local user.name "github-actions"
git pull
git add -A
git commit -m "Daily report update" -a
shell: bash
- name: Push changes
uses: ad-m/github-push-action@master
with:
github_token: ${{ inputs.githubToken }}
branch: ${{ inputs.branch }}
The steps here are quite long but pretty straightforward: check out the code (of this reports repository), install Python, install ghreport, make sure the report output directory exists in case this is a first run, generate the daily or weekly report as appropriate, commit it locally, and push the changes back. Many of these steps rely on official or 3rd party GitHub actions to do the stated work. I mostly figured out what to do here by doing Internet searches for “how do I <x> in GitHub actions?” and copy/pasted answers that I customized. If there are better ways of doing any of these steps I would be happy to hear about them.
The Python Team GitHub Action
# yaml-language-server: $schema=https://json.schemastore.org/github-action.json
name: "python-reports"
description: "Generates reports for Python team."
inputs:
repository:
description: "The GitHub repository to generate the report for."
required: true
githubToken:
description: "The Github token or PAT token (preferred) for API access."
required: true
weekly:
description: "Whether to generate a weekly report (else daily)."
required: false
default: false
count:
description: "Batch size for calls to Github API. Use if jobs are failing due to timeouts."
required: false
default: '25'
runs:
using: "composite"
steps:
- name: Set environment
run: |
echo "TEAM='gramster'" >> $GITHUB_ENV
echo -n "REPO='microsoft/" >> $GITHUB_ENV
echo -n ${{ inputs.repository }} >> $GITHUB_ENV
echo "'" >> $GITHUB_ENV
shell: bash
- name: Generate full report
if: inputs.weekly == 'true'
uses: gramster/github-issue-reporter@main
with:
repository: ${{ env.REPO }}
githubToken: ${{ inputs.githubToken }}
reportNameTemplate: 'fullreport.md'
reportPath: ${{ inputs.repository }}
all: true
team: ${{ env.TEAM }}
count: ${{ inputs.count }}
- name: Generate limited report
if: inputs.weekly != 'true'
uses: gramster/github-issue-reporter@main
with:
repository: ${{ env.REPO }}
githubToken: ${{ inputs.githubToken }}
reportPath: ${{ inputs.repository }}
team: ${{ env.TEAM }}
count: ${{ inputs.count }}
(I removed the full comma-separated list of team members and just left my name on line 26. It’s possible to use ghreport to get the team members if the token provided is from a user with admin rights, but that won’t get ex-team members and slows down the report generation process; providing an explicit list is a better option as the list changes rarely).
The main inputs are the access token, repository name, and type of report. It’s also possible to reduce the batch size used by ghreport, but I haven’t found that necessary.
The first step generates a script to set the environment as a way of passing parameters to further steps. If I remember correctly, I did this because I wanted to prepend ‘microsoft/’ to the repository name and didn’t know a different way to concatenate strings, but I don’t remember exactly; it may be this step is overkill and could be simplified;
The next two steps are conditional based on the report type; the first handles weekly reports while the second handles daily reports. The main difference is that the weekly report overrides the default property values in the next step for the all and reportNameTemplate properties.
The Workflows
Finally, we have on GitHub workflow for each report, in the .github/workflows folder of the repository. For example, here is the workflow for the Pylance daily report, that I showed an example of at the beginning:
name: 'Generate Daily Report for pylance'
on:
schedule:
- cron: 30 7 * * *
workflow_dispatch:
jobs:
report:
runs-on: ubuntu-18.04
timeout-minutes: 10
steps:
- id: report
uses: gramster/python-reports@main
with:
repository: 'pylance-release'
githubToken: ${{ secrets.GITHUB_TOKEN }}
This is pretty straightforward now; mostly I just need to give permissions to read issues and commit PRs, specify when the action should run (7:30am daily), and specify the repository and the token.
Customizing this for your use
If you wanted to make use of this on your own repo(s), I think the approach would vary based on whether you have just one repo or multiple. If you have multiple, I would suggest starting with creating a version of the ‘Python Team Github Action’ tailored to your organization, and then create workflows similar to mine above that use that. If you have just a single repo, that might be overkill, and you could just create a workflow that inlines steps from the ‘Python Team Github Action’ customized for your repo.
What’s Next?
These reports replicate just one part of prior automations and analyses I had. I also have quite a bit of code I wrote to do things like making sure we are following proper issue lifetime procedures, checking how well we are doing in terms of estimating issue time, monitoring bug rates (a feature already in ghreport if you generate HTML output), lead and cycle times, and so on. These all stem back to a period when we used ZenHub for project management, which we don’t anymore. I need to rewrite some of the code to play nicely with GitHub projects. Watch this space.