This is the third post in a series based off my Python for Data Science bootcamp I run at eBay occasionally. The other posts are:
This is an introduction to the NumPy and Pandas libraries that form the foundation of data science in Python. These libraries, especially Pandas, have a large API surface and many powerful features. There is now way in a short amount of time to cover every topic; in many cases we will just scratch the surface. But after this you should understand the fundamentals, have an idea of the overall scope, and have some pointers for extending your learning as you need more functionality.
Introduction
We’ll start by importing the numpy and pandas packages. Note the “as” aliases; it is conventional to use “np” for numpy and “pd” for pandas. If you are using Anaconda Python distribution, as recommended for data science, these packages should already be available:
import numpy as np
import pandas as pd
We are going to do some plotting with the matplotlib and Seaborn packages. We want the plots to appear as cell outputs inline in Jupyter. To do that we need to run this next line:
%matplotlib inline
We’re going to use the Seaborn library for better styled charts, and it may not yet be installed. To install it, if you are running at the command line and using Anaconda, use:
conda config --add channels conda-forge
conda install seaborn
Else use pip:
pip install seaborn
If you are running this in Jupyter from an Anaconda installation, use:
# sys.executable is the path to the Python executable; e.g. /usr/bin/python
import sys
!conda config --add channels conda-forge
!conda install --yes --prefix {sys.prefix} seaborn
We need to import the plotting packages. We’re also going to change the default style for matplotlib plots to use Seaborn’s styling:
import matplotlib.pyplot as plt
import seaborn as sns
# Call sns.set() to change the default styles for matplotlib to use Seaborn styles.
sns.set()
NumPy - the Foundation of Data Science in Python
Data science is largely about the manipulation of (often large) collections of numbers. To support effective data science a language needs a way to do this efficiently. Python lists are suboptimal because they are heterogeneous collections of object references; the objects in turn have reference counts for garbage collection, type info, size info, and the actual data. Thus storing (say) a list of a four 32-bit integers, rather than requiring just 16 bytes requires much more. Furthermore there is typically poor locality of the items referenced from the list, leading to cache misses and other performance problems. Python does offer an array type which is homogeneous and improves on lists as far as storage goes, but it offers limited operations on that data.
NumPy bridges the gap, offering both efficient storage of homogeneous data in single or multi-dimensional arrays, and a rich set of computationally -efficient operations on that data.
In this section we will cover some of the basics of NumPy. We won’t go into too much detail as our main focus will be Pandas, a library built on top of NumPy that is particularly well-suited to manipulating tabular data. You can get a deeper intro to NumPy here: https://docs.scipy.org/doc/numpy-dev/user/quickstart.html
# Create a one-dimensional NumPy array from a range
a = np.arange(1, 11)
a
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# Create a one-dimensional NumPy array from a range with a specified increment
a = np.arange(0.5, 10.5, 0.5)
a
array([ 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5,
5. , 5.5, 6. , 6.5, 7. , 7.5, 8. , 8.5, 9. ,
9.5, 10. ])
# Reshape the array into a 4x5 matrix
a = a.reshape(4, 5)
a
array([[ 0.5, 1. , 1.5, 2. , 2.5],
[ 3. , 3.5, 4. , 4.5, 5. ],
[ 5.5, 6. , 6.5, 7. , 7.5],
[ 8. , 8.5, 9. , 9.5, 10. ]])
# Get the shape and # of elements
print(np.shape(a))
print(np.size(a))
(4, 5)
20
# Create one dimensional NumPy array from a list
a = np.array([1, 2, 3])
a
array([1, 2, 3])
# Append a value
b = a
a = np.append(a, 4) # Note that this makes a copy; the original array is not affected
print(b)
print(a)
[1 2 3]
[1 2 3 4]
# Index and slice
print(f'Second element of a is {a[1]}')
print(f'Last element of a is {a[-1]}')
print(f'Middle two elements of a are {a[1:3]}')
Second element of a is 2
Last element of a is 4
Middle two elements of a are [2 3]
# Create an array of zeros of length n
np.zeros(5)
array([ 0., 0., 0., 0., 0.])
# Create an array of 1s
np.ones(5)
array([ 1., 1., 1., 1., 1.])
# Create an array of 10 random integers between 1 and 100
np.random.randint(1,100, 10)
array([52, 77, 50, 29, 31, 43, 14, 41, 25, 82])
# Create linearly spaced array of 5 values from 0 to 100
np.linspace(0, 100, 5)
array([ 0., 25., 50., 75., 100.])
# Create a 2-D array from a list of lists
b = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
b
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# Get the shape, # of elements, and # of dimensions
print(np.shape(b))
print(np.size(b))
print(np.ndim(b))
(3, 3)
9
2
# Get the first row of b; these are equivalent
print(b[0])
print(b[0,:]) # First row, "all columns"
[1 2 3]
[1 2 3]
# Get the first column of b
print(b[:,0])
[1 4 7]
# Get a subsection of b, from 1,1 through 2,2 (i.e. before 3,3)
print(b[1:3,1:3])
[[5 6]
[8 9]]
Numpy supports Boolean operations on arrays and using arrays of Boolean values to select elements:
# Get an array of Booleans based on whether entries are odd or even numbers
b%2 == 0
array([[False, True, False],
[ True, False, True],
[False, True, False]], dtype=bool)
# Use Boolean indexing to set all even values to -1
b[b%2 == 0] = -1
b
array([[ 1, -1, 3],
[-1, 5, -1],
[ 7, -1, 9]])
UFuncs
NumPy supports highly efficient low-level operations on arrays called UFuncs (Universal Functions).
np.mean(b) # Get the mean of all the elements
2.3333333333333335
np.power(b, 2) # Raise every element to second power
array([[ 1, 1, 9],
[ 1, 25, 1],
[49, 1, 81]])
You can get the details on UFuncs here: https://docs.scipy.org/doc/numpy-1.13.0/reference/ufuncs.html
Dates and Times in NumPy
NumPy uses 64-bit integers to represent datetimes:
np.array('2015-12-25', dtype=np.datetime64) # We use an array just so Jupyter will show us the type details
array(datetime.date(2015, 12, 25), dtype='datetime64[D]')
Note the “[D]” after the type. NumPy is flexible in how the 64-bits are allocated between date and time components. Because we specified a date only, it assumes the granularity is days, which is what the “D” means. There are a number of other possible units; the most useful are:
| Y | Years |
|---|---|
| M | Months |
| W | Weeks |
| D | Days |
| h | Hours |
| m | Minutes |
| s | Seconds |
| ms | Milliseconds |
| us | Microsecond |
Obviously the finer the granularity the more bits are assigned to fractional seconds leaving less for years so the range dates we can represent shrinks. The values are signed integers; in most cases 0 would be 0AD but for some very fine granularity units 0 is Jan 1, 1970 (e.g. “as” is attoseconds and the range here is less than 10 seconds either side of the start of 1970!).
There is also a default “ns” format suitable for most uses.
When constructing a NumPy datetime the units can be specified explicitly or inferred based on the initialization value’s format:
np.array(np.datetime64('2015-12-25 12:00:00.00')) # default to ms as that's the granularity in the datetime
array(datetime.datetime(2015, 12, 25, 12, 0), dtype='datetime64[ms]')
np.array(np.datetime64('2015-12-25 12:00:00.00', 'us')) # use microseconds
array(datetime.datetime(2015, 12, 25, 12, 0), dtype='datetime64[us]')
NumPy’s date parsing is very limited and for the most part we will use Pandas datetime types that we will discuss later.
Pandas
NumPy is primarily aimed at scientific computation e.g. linear algebra. As such, 2D data is in the form of arrays of arrays. In data science applications, we are more often dealing with tabular data; that is, collections of records (samples, observations) where each record may be heterogeneous but the schema is consistent from record to record. The Pandas library is built on top of NumPy to provide this type of representation of data, along with the types of operations more typical in data science applications, like indexing, filtering and aggregation. There are two primary classes it provides for this, Series and DataFrame.
Pandas Series
A Pandas Series is a one-dimensional array of indexed data. It wraps a sequence of values (a NumPy array) and a sequence of indices (a pd.Index object), along with a name. Pandas indexes can be thought of as immutable dictionaries mapping keys to locations/offsets in the value array; the dictionary implementation is very efficient and there are specialized versions for each type of index (int, float, etc).
For those interested, the underlying implementation used for indexes in Pandas is klib: https://github.com/attractivechaos/klib
squares = pd.Series([1, 4, 9, 16, 25])
print(squares.name)
squares
None
0 1
1 4
2 9
3 16
4 25
dtype: int64
From the above you can see that by default, a series will have numeric indices assigned, as a sequential list starting from 0, much like a typical Python list or array. The default name for the series is None, and the type of the data is int64.
squares.values
array([ 1, 4, 9, 16, 25])
squares.index
RangeIndex(start=0, stop=5, step=1)
You can show the first few lines with .head(). The argument, if omitted, defaults to 5.
squares.head(2)
0 1
1 4
dtype: int64
The data need not be numeric:
data = pd.Series(["quick", "brown", "fox"], name="Fox")
data
0 quick
1 brown
2 fox
Name: Fox, dtype: object
Above, we have assigned a name to the series, and note that the data type is now object. Think of Pandas object as being strings/text and/or None rather than generic Python objects; this is the predominant usage.
What if we combine integers and strings?
data = pd.Series([1, "quick", "brown", "fox"], name="Fox")
data
0 1
1 quick
2 brown
3 fox
Name: Fox, dtype: object
We can have “missing” values using None:
data = pd.Series(["quick", None, "fox"], name="Fox")
data
0 quick
1 None
2 fox
Name: Fox, dtype: object
For a series of type object, None can simply be included, but what if the series is numeric?
data = pd.Series([1, None, 3])
data
0 1.0
1 NaN
2 3.0
dtype: float64
As you can see, the special float value NaN (np.nan, for ’not a number’) is used in this case. This is also why the series has been changed to have type float64 and not int64; floating point numbers have special reserved values to represent NaN while ints don’t.
Be careful with NaN; it will fail equality tests:
np.nan == np.nan
False
Instead you can use is or np.isnan():
print(np.nan is np.nan)
print(np.isnan(np.nan))
True
True
Normal indexing and slicing operations are available, much like Python lists:
squares[2]
9
squares[2:4]
2 9
3 16
dtype: int64
Where NumPy arrays have implicit integer sequence indices, Pandas indices are explicit and need not be integers:
squares = pd.Series([1, 4, 9, 16, 25],
index=['square of 1', 'square of 2', 'square of 3', 'square of 4', 'square of 5'])
squares
square of 1 1
square of 2 4
square of 3 9
square of 4 16
square of 5 25
dtype: int64
squares['square of 3']
9
As you can see, a Series is a lot like a Python dict (with additional slicing like a list). In fact, we can construct one from a Python dict:
pd.Series({'square of 1':1, 'square of 2':4, 'square of 3':9, 'square of 4':16, 'square of 5':25})
square of 1 1
square of 2 4
square of 3 9
square of 4 16
square of 5 25
dtype: int64
You can use both a dictionary and an explicit index but be careful if the index and dictionary keys don’t align completely; the explicit index takes precedence. Look at what happens:
pd.Series({"one": 1, "three": 3}, index=["one", "two"])
one 1.0
two NaN
dtype: float64
Exercise 1
Given the list below, create a Series that has the list as both the index and the values, and then display the first 3 rows:
ex1 = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm']
A number of dict-style operations work on a Series:
'square of 5' in squares
True
squares.keys()
Index(['square of 1', 'square of 2', 'square of 3', 'square of 4',
'square of 5'],
dtype='object')
squares.items() # Iterable
<zip at 0x1a108c9f48>
list(squares.items())
[('square of 1', 1),
('square of 2', 4),
('square of 3', 9),
('square of 4', 16),
('square of 5', 25)]
However, unlike with a Python dict, .values is an array attribute, not a function returning an iterable, so we use .values, not .values():
squares.values
array([ 1, 4, 9, 16, 25])
We can add new entries:
squares['square of 6'] = 36
squares
square of 1 1
square of 2 4
square of 3 9
square of 4 16
square of 5 25
square of 6 36
dtype: int64
change existing values:
squares['square of 6'] = -1
squares
square of 1 1
square of 2 4
square of 3 9
square of 4 16
square of 5 25
square of 6 -1
dtype: int64
and delete entries:
del squares['square of 6']
squares
square of 1 1
square of 2 4
square of 3 9
square of 4 16
square of 5 25
dtype: int64
Iteration (.__iter__) iterates over the values in a Series, while membership testing (.__contains__) checks the indices. .iteritems() will iterate over (index, value) tuples, similar to list’s .enumerate():
for v in squares: # calls .__iter__()
print(v)
1
4
9
16
25
print(16 in squares)
print('square of 4' in squares) # calls .__contains__()
False
True
print(16 in squares.values)
True
for v in squares.iteritems():
print(v)
('square of 1', 1)
('square of 2', 4)
('square of 3', 9)
('square of 4', 16)
('square of 5', 25)
Vectorized Operations
You can iterate over a Series or Dataframe, but in many cases there are much more efficient vectorized UFuncs available; these are implemented in native code exploiting parallel processor operations and are much faster. Some examples are .sum(), .median(), .mode(), and .mean():
squares.mean()
11.0
Series also behaves a lot like a list. We saw some indexing and slicing earlier. This can be done on non-numeric indexes too, but be careful: it includes the final value:
squares['square of 2': 'square of 4']
square of 2 4
square of 3 9
square of 4 16
dtype: int64
If one or both of the keys are invalid, the results will be empty:
squares['square of 2': 'cube of 4']
Series([], dtype: int64)
Exercise 2
Delete the row ‘k’ from the earlier series you created in exercise 1, then display the rows from ‘f’ through ’l’.
Something to be aware of, is that the index need not be unique:
people = pd.Series(['alice', 'bob', 'carol'], index=['teacher', 'teacher', 'plumber'])
people
teacher alice
teacher bob
plumber carol
dtype: object
If we dereference a Series by a non-unique index we will get a Series, not a scalar!
people['plumber']
'carol'
people['teacher']
teacher alice
teacher bob
dtype: object
You need to be very careful with non-unique indices. For example, assignment will change all the values for that index without collapsing to a single entry!
people['teacher'] = 'dave'
people
teacher dave
teacher dave
plumber carol
dtype: object
To prevent this you could use positional indexing, but my advice is to try to avoid using non-unique indices if at all possible. You can use the .is_unique property on the index to check:
people.index.is_unique
False
DataFrames
A DataFrame is like a dictionary where the keys are column names and the values are Series that share the same index and hold the column values. The first “column” is actually the shared Series index (there are some exceptions to this where the index can be multi-level and span more than one column but in most cases it is flat).
names = pd.Series(['Alice', 'Bob', 'Carol'])
phones = pd.Series(['555-123-4567', '555-987-6543', '555-245-6789'])
dept = pd.Series(['Marketing', 'Accounts', 'HR'])
staff = pd.DataFrame({'Name': names, 'Phone': phones, 'Department': dept}) # 'Name', 'Phone', 'Department' are the column names
staff
| Department | Name | Phone | |
|---|---|---|---|
| 0 | Marketing | Alice | 555-123-4567 |
| 1 | Accounts | Bob | 555-987-6543 |
| 2 | HR | Carol | 555-245-6789 |
Note above that the first column with values 0, 1, 2 is actually the shared index, and there are three series keyed off the three names “Department”, “Name” and “Phone”.
Like Series, DataFrame has an index for rows:
staff.index
RangeIndex(start=0, stop=3, step=1)
DataFrame also has an index for columns:
staff.columns
Index(['Department', 'Name', 'Phone'], dtype='object')
staff.values
array([['Marketing', 'Alice', '555-123-4567'],
['Accounts', 'Bob', '555-987-6543'],
['HR', 'Carol', '555-245-6789']], dtype=object)
The index operator actually selects a column in the DataFrame, while the .iloc and .loc attributes still select rows (actually, we will see in the next section that they can select a subset of the DataFrame with a row selector and column selector, but the row selector comes first so if you supply a single argument to .loc or .iloc you will select rows):
staff['Name'] # Acts similar to dictionary; returns the Series for a column
0 Alice
1 Bob
2 Carol
Name: Name, dtype: object
staff.loc[2]
Department HR
Name Carol
Phone 555-245-6789
Name: 2, dtype: object
You can get a transpose of the DataFrame with the .T attribute:
staff.T
| 0 | 1 | 2 | |
|---|---|---|---|
| Department | Marketing | Accounts | HR |
| Name | Alice | Bob | Carol |
| Phone | 555-123-4567 | 555-987-6543 | 555-245-6789 |
You can also access columns like this, with dot-notation. Occasionally this breaks if there is a conflict with a UFunc name, like ‘count’:
staff.Name
0 Alice
1 Bob
2 Carol
Name: Name, dtype: object
You can add new columns. Later we’ll see how to do this as a function of existing columns:
staff['Fulltime'] = True
staff.head()
| Department | Name | Phone | Fulltime | |
|---|---|---|---|---|
| 0 | Marketing | Alice | 555-123-4567 | True |
| 1 | Accounts | Bob | 555-987-6543 | True |
| 2 | HR | Carol | 555-245-6789 | True |
Use .describe() to get summary statistics:
staff.describe()
| Department | Name | Phone | Fulltime | |
|---|---|---|---|---|
| count | 3 | 3 | 3 | 3 |
| unique | 3 | 3 | 3 | 1 |
| top | Accounts | Alice | 555-123-4567 | True |
| freq | 1 | 1 | 1 | 3 |
Use .quantile() to get quantiles:
df = pd.DataFrame([2, 3, 1, 4, 3, 5, 2, 6, 3])
df.quantile(q=[0.25, 0.75])
| 0 | |
|---|---|
| 0.25 | 2.0 |
| 0.75 | 4.0 |
Use .drop() to remove rows. This will return a copy with the modifications and leave the original untouched unless you include the argument inplace=True.
staff.drop([1])
| Department | Name | Phone | Fulltime | |
|---|---|---|---|---|
| 0 | Marketing | Alice | 555-123-4567 | True |
| 2 | HR | Carol | 555-245-6789 | True |
# Note that because we didn't say inplace=True,
# the original is unchanged
staff
| Department | Name | Phone | Fulltime | |
|---|---|---|---|---|
| 0 | Marketing | Alice | 555-123-4567 | True |
| 1 | Accounts | Bob | 555-987-6543 | True |
| 2 | HR | Carol | 555-245-6789 | True |
There are many ways to construct a DataFrame. For example, from a Series or dictionary of Series, from a list of Python dicts, or from a 2-D NumPy array. There are also utility functions to read data from disk into a DataFrame, e.g. from a .csv file or an Excel spreadsheet. We’ll cover some of these later.
Many DataFrame operations take an axis argument which defaults to zero. This specifies whether we want to apply the operation by rows (axis=0) or by columns (axis=1).
You can drop columns if you specify axis=1:
staff.drop(["Fulltime"], axis=1)
| Department | Name | Phone | |
|---|---|---|---|
| 0 | Marketing | Alice | 555-123-4567 |
| 1 | Accounts | Bob | 555-987-6543 |
| 2 | HR | Carol | 555-245-6789 |
Another way to remove a column in-place is to use del:
del staff["Department"]
staff
| Name | Phone | Fulltime | |
|---|---|---|---|
| 0 | Alice | 555-123-4567 | True |
| 1 | Bob | 555-987-6543 | True |
| 2 | Carol | 555-245-6789 | True |
You can change the index to be some other column. If you want to save the existing index, then first add it as a new column:
staff['Number'] = staff.index
staff
| Name | Phone | Fulltime | Number | |
|---|---|---|---|---|
| 0 | Alice | 555-123-4567 | True | 0 |
| 1 | Bob | 555-987-6543 | True | 1 |
| 2 | Carol | 555-245-6789 | True | 2 |
# Now we can set the new index. This is a destructive
# operation that discards the old index, which is
# why we saved it as a new column first.
staff = staff.set_index('Name')
staff
| Phone | Fulltime | Number | |
|---|---|---|---|
| Name | |||
| Alice | 555-123-4567 | True | 0 |
| Bob | 555-987-6543 | True | 1 |
| Carol | 555-245-6789 | True | 2 |
Alternatively you can promote the index to a column and go back to a numeric index with reset_index():
staff = df.reset_index()
staff
| index | 0 | |
|---|---|---|
| 0 | 0 | 2 |
| 1 | 1 | 3 |
| 2 | 2 | 1 |
| 3 | 3 | 4 |
| 4 | 4 | 3 |
| 5 | 5 | 5 |
| 6 | 6 | 2 |
| 7 | 7 | 6 |
| 8 | 8 | 3 |
Exercise 3
Create a DataFrame from the dictionary below:
ex3data = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],
'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
Then:
- Generate a summary of the data
- Calculate the sum of all visits (the total number of visits).
More on Indexing
The Pandas Index type can be thought of as an immutable ordered multiset (multiset as indices need not be unique). The immutability makes it safe to share an index between multiple columns of a DataFrame. The set-like properties are useful for things like joins (a join is like an intersection between Indexes). There are dict-like properties (index by label) and list-like properties too (index by location).
Indexes are complicated but understanding them is key to leveraging the power of pandas. Let’s look at some example operations to get more familiar with how they work:
# Let's create two Indexes for experimentation
i1 = pd.Index([1, 3, 5, 7, 9])
i2 = pd.Index([2, 3, 5, 7, 11])
You can index like a list with []:
i1[2]
5
You can also slice like a list:
i1[2:5]
Int64Index([5, 7, 9], dtype='int64')
The normal Python bitwise operators have set-like behavior on indices; this is very useful when comparing two dataframes that have similar indexes:
i1 & i2 # Intersection
Int64Index([3, 5, 7], dtype='int64')
i1 | i2 # Union
Int64Index([1, 2, 3, 5, 7, 9, 11], dtype='int64')
i1 ^ i2 # Difference
Int64Index([1, 2, 9, 11], dtype='int64')
Series and DataFrames have an explicit Index but they also have an implicit index like a list. When using the [] operator, the type of the argument will determine which index is used:
s = pd.Series([1, 2], index=["1", "2"])
print(s["1"]) # matches index type; use explicit
print(s[1]) # integer doesn't match index type; use implicit positional
1
2
If the explicit Index uses integer values things can get confusing. In such cases it is good to make your intent explicit; there are attributes for this:
.locreferences the explicit Index.ilocreferences the implicit Index; i.e. a positional index 0, 1, 2,…
The Python way is “explicit is better than implicit” so when indexing/slicing it is better to use these. The example below illustrates the difference:
# Note: explicit index starts at 1; implicit index starts at 0
nums = pd.Series(['first', 'second', 'third', 'fourth'], index=[1, 2, 3, 4])
print(f'Item at explicit index 1 is {nums.loc[1]}')
print(f'Item at implicit index 1 is {nums.iloc[1]}')
print(nums.loc[1:3])
print(nums.iloc[1:3])
Item at explicit index 1 is first
Item at implicit index 1 is second
1 first
2 second
3 third
dtype: object
2 second
3 third
dtype: object
When using .iloc, the expression in [] can be:
- an integer, a list of integers, or a slice object (e.g.
1:7) - a Boolean array (see Filtering section below for why this is very useful)
- a function with one argument (the calling object) that returns one of the above
Selecting outside of the bounds of the object will raise an IndexError except when using slicing.
When using .loc, the expression in [] can be:
- an label, a list of labels, or a slice object with labels (e.g.
'a':'f'; unlike normal slices the stop label is included in the slice) - a Boolean array
- a function with one argument (the calling object) that returns one of the above
You can use one or two dimensions in [] after .loc or .iloc depending on whether you want to select a subset of rows, columns, or both.
You can use the set_index method to change the index of a DataFrame.
If you want to change entries in a DataFrame selectively to some other value, you can use assignment with indexing, such as:
df.loc[row_indexer, column_indexer] = value
Don’t use:
df[row_indexer][column_indexer] = value
That chained indexing can result in copies being made which will not have the effect you expect. You want to do all your indexing in one operation. See the details at https://pandas.pydata.org/pandas-docs/stable/indexing.html
Exercise 4
Using the same DataFrame from Exercise 3:
- Select just the ‘animal’ and ‘age’ columns from the DataFrame
- Select the data in rows [3, 5, 7] and in columns [‘animal’, ‘age’]
Loading/Saving CSV, JSON and Excel Files
Use Pandas.read_csv to read a CSV file into a dataframe. There are many optional argumemts that you can provide, for example to set or override column headers, skip initial rows, treat first row as containing column headers, specify the type of columns (Pandas will try to infer these otherwise), skip columns, and so on. The parse_dates argument is especially useful for specifying which columns have date fields as Pandas doesn’t infer these.
Full docs are at https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
crime = pd.read_csv('http://samplecsvs.s3.amazonaws.com/SacramentocrimeJanuary2006.csv',
parse_dates=['cdatetime'])
crime.head()
| cdatetime | address | district | beat | grid | crimedescr | ucr_ncic_code | latitude | longitude | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2006-01-01 | 3108 OCCIDENTAL DR | 3 | 3C | 1115 | 10851(A)VC TAKE VEH W/O OWNER | 2404 | 38.550420 | -121.391416 |
| 1 | 2006-01-01 | 2082 EXPEDITION WAY | 5 | 5A | 1512 | 459 PC BURGLARY RESIDENCE | 2204 | 38.473501 | -121.490186 |
| 2 | 2006-01-01 | 4 PALEN CT | 2 | 2A | 212 | 10851(A)VC TAKE VEH W/O OWNER | 2404 | 38.657846 | -121.462101 |
| 3 | 2006-01-01 | 22 BECKFORD CT | 6 | 6C | 1443 | 476 PC PASS FICTICIOUS CHECK | 2501 | 38.506774 | -121.426951 |
| 4 | 2006-01-01 | 3421 AUBURN BLVD | 2 | 2A | 508 | 459 PC BURGLARY-UNSPECIFIED | 2299 | 38.637448 | -121.384613 |
If you need to do some preprocessing of a field during loading you can use the converters argument which takes a dictionary mapping the field names to functions that transform the field. E.g. if you had a string field zip and you wanted to take just the first 3 digits, you could use:
..., converters={'zip': lambda x: x[:3]}, ...
If you know what types to expect for the columns, you can (and, IMO, you should) pass a dictionary in with the types argument that maps field names to NumPy types, to override the type inference. You can see details of NumPy scalar types here: https://docs.scipy.org/doc/numpy-1.13.0/reference/arrays.scalars.html. Omit any fields that you may have already included in the parse_dates argument.
By default the first line is expected to contain the column headers. If it doesn’t you can specify them yourself, using arguments such as:
..., header=None, names=['column1name','column2name'], ...
If the separator is not a comma, use the sep argument; e.g. for a TAB-separated file:
..., sep='\t', ...
Use Pandas.read_excel to load spreadsheet data. Full details here: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
titanic = pd.read_excel('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls')
titanic.head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON |
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
Use the DataFrame.to_csv method to save a DataFrame to a file or DataFrame.to_excel to save as a spreadsheet.
It’s also possible to read JSON data into a DataFrame. The complexity here is that JSON data is typically hierarchical; in order to turn it into a DataFrame the data typically needs to be flattened in some way. This is controlled by an orient parameter. For details see https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_json.html.
Sorting
You can sort a DataFrame using the sort_values method:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, na_position='last')
The by argument should be a column name or list of column names in priority order (if axis=0, i.e. we are sorting the rows, which is typically the case).
See https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.sort_values.html for the details.
Filtering
A Boolean expression on a Series will return a Series of Booleans:
titanic.survived == 1
0 True
1 True
2 False
3 False
4 False
5 True
6 True
7 False
8 True
9 False
10 False
11 True
12 True
13 True
14 True
15 False
16 False
17 True
18 True
19 False
20 True
21 True
22 True
23 True
24 True
25 False
26 True
27 True
28 True
29 True
...
1279 False
1280 False
1281 False
1282 False
1283 False
1284 False
1285 False
1286 True
1287 False
1288 False
1289 False
1290 True
1291 False
1292 False
1293 False
1294 False
1295 False
1296 False
1297 False
1298 False
1299 False
1300 True
1301 False
1302 False
1303 False
1304 False
1305 False
1306 False
1307 False
1308 False
Name: survived, Length: 1309, dtype: bool
If you index a Series with a Boolean Series, you will select the items where the index is True. For example:
titanic[titanic.survived == 1].head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 5 | 1 | 1 | Anderson, Mr. Harry | male | 48.0000 | 0 | 0 | 19952 | 26.5500 | E12 | S | 3 | NaN | New York, NY |
| 6 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63.0000 | 1 | 0 | 13502 | 77.9583 | D7 | S | 10 | NaN | Hudson, NY |
| 8 | 1 | 1 | Appleton, Mrs. Edward Dale (Charlotte Lamson) | female | 53.0000 | 2 | 0 | 11769 | 51.4792 | C101 | S | D | NaN | Bayside, Queens, NY |
You can combine these with & (and) and | (or). Pandas uses these bitwise operators because Python allows them to be overloaded while ‘and’ and ‘or’ cannot be, and in any event they arguably make sense as they are operating on Boolean series which are similar to bit vectors.
As & and | have higher operator precedence than relational operators like > and ==, the subexpressions we use with them need to be enclosed in parentheses:
titanic[titanic.survived & (titanic.sex == 'female') & (titanic.age > 50)].head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 1 | 1 | Andrews, Miss. Kornelia Theodosia | female | 63.0 | 1 | 0 | 13502 | 77.9583 | D7 | S | 10 | NaN | Hudson, NY |
| 8 | 1 | 1 | Appleton, Mrs. Edward Dale (Charlotte Lamson) | female | 53.0 | 2 | 0 | 11769 | 51.4792 | C101 | S | D | NaN | Bayside, Queens, NY |
| 33 | 1 | 1 | Bonnell, Miss. Elizabeth | female | 58.0 | 0 | 0 | 113783 | 26.5500 | C103 | S | 8 | NaN | Birkdale, England Cleveland, Ohio |
| 42 | 1 | 1 | Brown, Mrs. John Murray (Caroline Lane Lamson) | female | 59.0 | 2 | 0 | 11769 | 51.4792 | C101 | S | D | NaN | Belmont, MA |
| 43 | 1 | 1 | Bucknell, Mrs. William Robert (Emma Eliza Ward) | female | 60.0 | 0 | 0 | 11813 | 76.2917 | D15 | C | 8 | NaN | Philadelphia, PA |
NumPy itself also supports such Boolean filtering; for example:
s = np.array([3, 2, 4, 1, 5])
s[s > np.mean(s)] # Get the values above the mean
array([4, 5])
Handling Missing Data
To see if there are missing values, we can use isnull() to get a DataFrame where there are null values:
titanic.isnull().head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | False | False | True | False |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False | True | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False | True | True | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False | True | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | False | True | True | False |
The above will show us the first few rows that had null values. If we want to know which columns may have nulls, we can use:
titanic.isnull().any()
pclass False
survived False
name False
sex False
age True
sibsp False
parch False
ticket False
fare True
cabin True
embarked True
boat True
body True
home.dest True
dtype: bool
.any() returns True if any are true; .all() returns True if all are true.
To drop rows that have missing values, use dropna(); add inplace=True to do it in place.
titanic.dropna().head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest |
|---|
In this case there are none - no-one could both be on a boat and be a recovered body, so at least one of these fields is always NaN.
It may be more useful to be selective. For example, if we want to get the rows in which ticket and cabin are not null:
filter = titanic.notnull()
filter.head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | True | True | True | True | True | True | True | True | True | True | True | False | True |
| 1 | True | True | True | True | True | True | True | True | True | True | True | True | False | True |
| 2 | True | True | True | True | True | True | True | True | True | True | True | False | False | True |
| 3 | True | True | True | True | True | True | True | True | True | True | True | False | True | True |
| 4 | True | True | True | True | True | True | True | True | True | True | True | False | False | True |
titanic[filter.ticket & filter.cabin].head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON |
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
We can use .count() to get the number of entries in each column that are not null.
titanic.count()
pclass 1309
survived 1309
name 1309
sex 1309
age 1046
sibsp 1309
parch 1309
ticket 1309
fare 1308
cabin 295
embarked 1307
boat 486
body 121
home.dest 745
dtype: int64
To replace missing values with values of our choosing, we use .fillna(). With a single scalar argument it will replace all null entries in the DataFrame with that value. Usually we will want to be more granular and control which columns are affected in what ways. Let’s see if there are rows with no fare specified:
titanic[~filter.fare]
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1225 | 3 | 0 | Storey, Mr. Thomas | male | 60.5 | 0 | 0 | 3701 | NaN | NaN | S | NaN | 261.0 | NaN |
We can change the fare to zero by passing a dictionary as the argument rather than a scalar:
titanic.fillna({'fare': 0}, inplace=True)
titanic[~filter.fare]
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1225 | 3 | 0 | Storey, Mr. Thomas | male | 60.5 | 0 | 0 | 3701 | 0.0 | NaN | S | NaN | 261.0 | NaN |
We could also use a method="ffill" argument for a forward fill or method="bfill" argument for a backward fill; these are most useful for time series data. Yet another option is to use the .interpolate() method to use interpolation for the missing values; that is beyond the scope of this notebook.
Exercise 5
Using the previous DataFrame from exercise 3, do the following:
- Select only the rows where the number of visits is greater than or equal to 3
- Select the rows where the age is missing, i.e. is NaN
- Select the rows where the animal is a cat and the age is less than 3
- Select the rows the age is between 2 and 4 (inclusive)
- Change the index to use this list:
idx = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'] - Change the age in row ‘f’ to 1.5.
- Append a new row ‘k’ to df with your choice of values for each column
- Then delete that row to return the original DataFrame
Concatenation
pandas.concat can be used to concatenate Series and DataFrames:
s1 = pd.Series(['A', 'B', 'C'])
s2 = pd.Series(['D', 'E', 'F'])
df = pd.concat([s1, s2])
df
0 A
1 B
2 C
0 D
1 E
2 F
dtype: object
Note that the Indexes are concatenated too, so if you are using a simple row number index you can end up with duplicate values.
df[2]
2 C
2 F
dtype: object
If you don’t want this behavior use the ignore_index argument; a new index will be generated:
pd.concat([s1, s2], ignore_index=True)
0 A
1 B
2 C
3 D
4 E
5 F
dtype: object
Alternatively you can use verify_integrity=True to cause an exception to be raised if the result would have duplicate indices.
pd.concat([s1, s2], verify_integrity=True)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-108-c7992d77592a> in <module>()
----> 1 pd.concat([s1, s2], verify_integrity=True)
~/anaconda/lib/python3.6/site-packages/pandas/core/reshape/concat.py in concat(objs, axis, join, join_axes, ignore_index, keys, levels, names, verify_integrity, copy)
210 keys=keys, levels=levels, names=names,
211 verify_integrity=verify_integrity,
--> 212 copy=copy)
213 return op.get_result()
214
~/anaconda/lib/python3.6/site-packages/pandas/core/reshape/concat.py in __init__(self, objs, axis, join, join_axes, keys, levels, names, ignore_index, verify_integrity, copy)
361 self.copy = copy
362
--> 363 self.new_axes = self._get_new_axes()
364
365 def get_result(self):
~/anaconda/lib/python3.6/site-packages/pandas/core/reshape/concat.py in _get_new_axes(self)
441 new_axes[i] = ax
442
--> 443 new_axes[self.axis] = self._get_concat_axis()
444 return new_axes
445
~/anaconda/lib/python3.6/site-packages/pandas/core/reshape/concat.py in _get_concat_axis(self)
498 self.levels, self.names)
499
--> 500 self._maybe_check_integrity(concat_axis)
501
502 return concat_axis
~/anaconda/lib/python3.6/site-packages/pandas/core/reshape/concat.py in _maybe_check_integrity(self, concat_index)
507 overlap = concat_index.get_duplicates()
508 raise ValueError('Indexes have overlapping values: '
--> 509 '{overlap!s}'.format(overlap=overlap))
510
511
ValueError: Indexes have overlapping values: [0, 1, 2]
d1 = pd.DataFrame([['A1', 'B1'],['A2', 'B2']], columns=['A', 'B'])
d2 = pd.DataFrame([['C3', 'D3'],['C4', 'D4']], columns=['A', 'B'])
d3 = pd.DataFrame([['B1', 'C1'],['B2', 'C2']], columns=['B', 'C'])
pd.concat([d1, d2])
| A | B | |
|---|---|---|
| 0 | A1 | B1 |
| 1 | A2 | B2 |
| 0 | C3 | D3 |
| 1 | C4 | D4 |
We can join on other axis too:
pd.concat([d1, d2], axis=1)
| A | B | A | B | |
|---|---|---|---|---|
| 0 | A1 | B1 | C3 | D3 |
| 1 | A2 | B2 | C4 | D4 |
pd.concat([d1, d3], axis=1)
| A | B | B | C | |
|---|---|---|---|---|
| 0 | A1 | B1 | B1 | C1 |
| 1 | A2 | B2 | B2 | C2 |
If the columns are not completely shared, additional NaN entries will be made:
pd.concat([d1, d3])
| A | B | C | |
|---|---|---|---|
| 0 | A1 | B1 | NaN |
| 1 | A2 | B2 | NaN |
| 0 | NaN | B1 | C1 |
| 1 | NaN | B2 | C2 |
We can force concat to only include the columns that are shared with an inner join:
pd.concat([d1, d3], join='inner')
| B | |
|---|---|
| 0 | B1 |
| 1 | B2 |
| 0 | B1 |
| 1 | B2 |
See https://pandas.pydata.org/pandas-docs/stable/generated/pandas.concat.html for more options.
Merging and Joining
We have already seen how we can add a new column to a DataFrame when it is a fixed scalar value:
df = pd.DataFrame(['Fred', 'Alice', 'Joe'], columns=['Name'])
df
| Name | |
|---|---|
| 0 | Fred |
| 1 | Alice |
| 2 | Joe |
df['Married'] = False
df
| Name | Married | |
|---|---|---|
| 0 | Fred | False |
| 1 | Alice | False |
| 2 | Joe | False |
We can also give an array of values provided it has the same length, or we can use a Series keyed on the index if it is not the same length:
df['Phone'] = ['555-123-4567', '555-321-0000', '555-999-8765']
df
| Name | Married | Phone | |
|---|---|---|---|
| 0 | Fred | False | 555-123-4567 |
| 1 | Alice | False | 555-321-0000 |
| 2 | Joe | False | 555-999-8765 |
df['Department'] = pd.Series({0: 'HR', 2: 'Marketing'})
df
| Name | Married | Phone | Department | |
|---|---|---|---|---|
| 0 | Fred | False | 555-123-4567 | HR |
| 1 | Alice | False | 555-321-0000 | NaN |
| 2 | Joe | False | 555-999-8765 | Marketing |
Often we want to join two DataFrames instead. Pandas has a merge function that supports one-to-one, many-to-one and many-to-many joins. merge will look for matching column names between the inputs and use this as the key:
d1 = pd.DataFrame({'city': ['Seattle', 'Boston', 'New York'], 'population': [704352, 673184, 8537673]})
d2 = pd.DataFrame({'city': ['Boston', 'New York', 'Seattle'], 'area': [48.42, 468.48, 142.5]})
pd.merge(d1, d2)
| city | population | area | |
|---|---|---|---|
| 0 | Seattle | 704352 | 142.50 |
| 1 | Boston | 673184 | 48.42 |
| 2 | New York | 8537673 | 468.48 |
You can explicitly specify the column to join on; this is equivalent to the above example:
pd.merge(d1, d2, on='city')
| city | population | area | |
|---|---|---|---|
| 0 | Seattle | 704352 | 142.50 |
| 1 | Boston | 673184 | 48.42 |
| 2 | New York | 8537673 | 468.48 |
If there is more than one column in common, only items where the column values match in all cases will be included. Let’s add a common column x and see what happens:
d10 = pd.DataFrame({'city': ['Seattle', 'Boston', 'New York'],
'x': ['a', 'b', 'c'],
'population': [704352, 673184, 8537673]})
d11 = pd.DataFrame({'city': ['Boston', 'New York', 'Seattle'],
'x': ['a', 'c', 'b'],
'area': [48.42, 468.48, 142.5]})
pd.merge(d10, d11)
| city | population | x | area | |
|---|---|---|---|---|
| 0 | New York | 8537673 | c | 468.48 |
You can see that Pandas avoided ambiguous cases by just dropping them.
However, if we specify the column for the join, Pandas will just treat the other common columns (if any) as distinct, and add suffixes to disambiguate the names:
pd.merge(d10, d11, on='city')
| city | population | x_x | area | x_y | |
|---|---|---|---|---|---|
| 0 | Seattle | 704352 | a | 142.50 | b |
| 1 | Boston | 673184 | b | 48.42 | a |
| 2 | New York | 8537673 | c | 468.48 | c |
If the column names to join on don’t match you can specify the names to use explicitly:
d3 = pd.DataFrame({'place': ['Boston', 'New York', 'Seattle'], 'area': [48.42, 468.48, 142.5]})
pd.merge(d1, d3, left_on='city', right_on='place')
| city | population | area | place | |
|---|---|---|---|---|
| 0 | Seattle | 704352 | 142.50 | Seattle |
| 1 | Boston | 673184 | 48.42 | Boston |
| 2 | New York | 8537673 | 468.48 | New York |
# If you want to drop the redundant column:
pd.merge(d1, d3, left_on='city', right_on='place').drop('place', axis=1)
| city | population | area | |
|---|---|---|---|
| 0 | Seattle | 704352 | 142.50 |
| 1 | Boston | 673184 | 48.42 |
| 2 | New York | 8537673 | 468.48 |
merge joins on arbitrary columns; if you want to join on the index you can use left_index and right_index:
df1 = pd.DataFrame(list('ABC'), columns=['c1'])
df2 = pd.DataFrame(list('DEF'), columns=['c2'])
pd.merge(df1, df2, left_index=True, right_index=True)
| c1 | c2 | |
|---|---|---|
| 0 | A | D |
| 1 | B | E |
| 2 | C | F |
Pandas provides a utility method on DataFrame, join, to do the above:
df1.join(df2)
| c1 | c2 | |
|---|---|---|
| 0 | A | D |
| 1 | B | E |
| 2 | C | F |
merge can take a how argument that can be inner (intersection), outer (union), left (first augmented by second) or right (second augmented by first) to control the type of join. inner joins are the default.
If there are other columns with the same name between the two DataFrames, Pandas will give them unique names by appending _x to the columns from the first argument and _y to the columns from the second argument.
It’s also possible to use lists of column names for the left_on and right_on arguments to join on multiple columns.
For more info on merging see https://pandas.pydata.org/pandas-docs/stable/merging.html
Exploring the Data
There are some more useful ways to explore the data in our DataFrame. Let’s return to the Titanic data set, but this time we will use the sample dataset that comes with Seaborn, which is a bit different to the one we loaded before:
import seaborn as sns;
titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
You can use .unique() to see the full set of distinct values in a series:
titanic.deck.unique()
[NaN, C, E, G, D, A, B, F]
Categories (7, object): [C, E, G, D, A, B, F]
.value_counts() will get the counts of the unique values:
titanic.deck.value_counts()
C 59
B 47
D 33
E 32
A 15
F 13
G 4
Name: deck, dtype: int64
.describe() will give summary statistics on a DataFrame. We first drop rows with NAs:
titanic.dropna().describe()
| survived | pclass | age | sibsp | parch | fare | |
|---|---|---|---|---|---|---|
| count | 182.000000 | 182.000000 | 182.000000 | 182.000000 | 182.000000 | 182.000000 |
| mean | 0.675824 | 1.192308 | 35.623187 | 0.467033 | 0.478022 | 78.919735 |
| std | 0.469357 | 0.516411 | 15.671615 | 0.645007 | 0.755869 | 76.490774 |
| min | 0.000000 | 1.000000 | 0.920000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 1.000000 | 24.000000 | 0.000000 | 0.000000 | 29.700000 |
| 50% | 1.000000 | 1.000000 | 36.000000 | 0.000000 | 0.000000 | 57.000000 |
| 75% | 1.000000 | 1.000000 | 47.750000 | 1.000000 | 1.000000 | 90.000000 |
| max | 1.000000 | 3.000000 | 80.000000 | 3.000000 | 4.000000 | 512.329200 |
Aggregating, Pivot Tables, and Multi-indexes
There is a common set of operations known as the split-apply-combine pattern:
- split the data into groups based on some criteria (this is a
GROUP BYin SQL, orgroupbyin Pandas) - apply some aggregate function on the groups, such as finding the mean for of some column for each group
- combining the results into a new table (Dataframe)
Let’s look at some examples. We can see the survival rates by gender by grouping by gender, and aggegating the survival feature using .mean():
titanic.groupby('sex')['survived'].mean()
sex
female 0.742038
male 0.188908
Name: survived, dtype: float64
Similarly it’s interesting to see the survival rate by passenger class; we’ll still group by gender as well:
titanic.groupby(['sex', 'class'])['survived'].mean()
sex class
female First 0.968085
Second 0.921053
Third 0.500000
male First 0.368852
Second 0.157407
Third 0.135447
Name: survived, dtype: float64
Because we grouped by two columns, the DataFrame result this time is a hierarchical table; an example of a multi-indexed DataFrame (indexed by both ‘sex’ and ‘class’). We’re mostly going to ignore those in this notebook - you can read about them here - but it is worth noting that Pandas has an unstack method that can turn a mutiply-indexed DataFrame back into a conventionally-indexed one. Each call to unstack will flatten out one level of a multi-index hierarchy (starting at the innermost, by default, although you can control this). There is also a stack method that does the opposite. Let’s repeat the above but unstack the result:
titanic.groupby(['sex', 'class'])['survived'].mean().unstack()
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
You may recognize the result as a pivot of the hierachical table. Pandas has a convenience method pivot_table to do all of the above in one go. It can take an aggfunc argument to specify how to aggregate the results; the default is to find the mean which is just what we want so we can omit it:
titanic.pivot_table('survived', index='sex', columns='class')
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
We could have pivoted the other way:
titanic.pivot_table('survived', index='class', columns='sex')
| sex | female | male |
|---|---|---|
| class | ||
| First | 0.968085 | 0.368852 |
| Second | 0.921053 | 0.157407 |
| Third | 0.500000 | 0.135447 |
If we wanted counts instead, we could use Numpy’s sum function to aggregate:
titanic.pivot_table('survived', index='sex', columns='class', aggfunc='sum')
| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 91 | 70 | 72 |
| male | 45 | 17 | 47 |
You can see more about what aggregation functions are available here. Let’s break things down further by age group (under 18 or over 18). To do this we will create a new series with the age range of each observation, using the cut function:
age = pd.cut(titanic['age'], [0, 18, 100]) # Assume no-one is over 100
age.head()
0 (18, 100]
1 (18, 100]
2 (18, 100]
3 (18, 100]
4 (18, 100]
Name: age, dtype: category
Categories (2, interval[int64]): [(0, 18] < (18, 100]]
Now we can create our pivot table using the age series as one of the indices! Pretty cool!
titanic.pivot_table('survived', index=['sex', age], columns='class')
| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 100] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 100] | 0.375000 | 0.071429 | 0.133663 |
Applying Functions
We saw earlier that we can add new columns to a DataFrame easily. The new column can be a function of an existing column. For example, we could add an ‘is_adult’ field to the Titanic data:
titanic['is_adult'] = titanic.age >= 18
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | is_adult | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False | True |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False | True |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False | True |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True | True |
That’s a simple case; we can do more complex row-by-row applications of arbitrary functions; here’s the same change done differently (this would be much less efficient but may be the only option if the function is complex):
titanic['is_adult'] = titanic.apply(lambda row: row['age'] >= 18, axis=1)
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | is_adult | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False | True |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False | True |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False | True |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True | True |
Exercise 6
Use the same DataFrame from exercise 5:
- Calculate the mean age for each different type of animal
- Count the number of each type of animal
- Sort the data first by the values in the ‘age’ column in decending order, then by the value in the ‘visits’ column in ascending order.
- In the ‘animal’ column, change the ‘snake’ entries to ‘python’
- The ‘priority’ column contains the values ‘yes’ and ’no’. Replace this column with a column of boolean values: ‘yes’ should be True and ’no’ should be False
String Operations
Pandas has vectorized string operations that will skip over missing values. Looks look at some examples:
# Let's get the more detailed Titanic data set
titanic3 = pd.read_excel('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls')
titanic3.head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON |
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
# Upper-case the home.dest field
titanic3['home.dest'].str.upper().head()
0 ST LOUIS, MO
1 MONTREAL, PQ / CHESTERVILLE, ON
2 MONTREAL, PQ / CHESTERVILLE, ON
3 MONTREAL, PQ / CHESTERVILLE, ON
4 MONTREAL, PQ / CHESTERVILLE, ON
Name: home.dest, dtype: object
# Let's split the field up into two
place_df = titanic3['home.dest'].str.split('/', expand=True) # Expands the split list into DF columns
place_df.columns = ['home', 'dest', ''] # For some reason there is a third column
titanic3['home'] = place_df['home']
titanic3['dest'] = place_df['dest']
titanic3 = titanic3.drop(['home.dest'], axis=1)
titanic3.head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home | dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO | None |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ | Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ | Chesterville, ON |
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ | Chesterville, ON |
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ | Chesterville, ON |
Ordinal and Categorical Data
So far we have mostly seen numeric, date-related, and “object” or string data. When loading data, Pandas will try to infer if it is numeric, but fall back to string/object. Loading functions like read_csv take arguments that can let us explicitly tell Pandas what the type of a column is, or whether it should try to parse the values in a column as dates. However, there are other types that are common where Pandas will need more help.
Categorical data is data where the values fall into a finite set of non-numeric values. Examples could be month names, department names, or occupations. It’s possible to represent these as strings but generally much more space and time efficient to map the values to some more compact underlying representation. Ordinal data is categorical data where the values are also ordered; for example, exam grades like ‘A’, ‘B’, ‘C’, etc, or statements of preference (‘Dislike’, ‘Neutral’, ‘Like’). In terms of use, the main difference is that it is valid to compare categorical data for equality only, while for ordinal values sorting, or comparing with relational operators like ‘>’, is meaningful (of course in practice we often sort categorical values alphabetically, but that is mostly a convenience and doesn’t usually imply relative importance or weight). It’s useful to think of ordinal and categorical data as being similar to enumerations in programming languages that support these.
Let’s look at some examples. We will use a dataset with automobile data from the UCI Machine Learning Repository. This data has ‘?’ for missing values so we need to specify that to get the right conversion. It’s also missing a header line so we need to supply names for the columns:
autos = pd.read_csv("http://mlr.cs.umass.edu/ml/machine-learning-databases/autos/imports-85.data", na_values='?',
header=None, names=[
"symboling", "normalized_losses", "make", "fuel_type", "aspiration",
"num_doors", "body_style", "drive_wheels", "engine_location",
"wheel_base", "length", "width", "height", "curb_weight",
"engine_type", "num_cylinders", "engine_size", "fuel_system",
"bore", "stroke", "compression_ratio", "horsepower", "peak_rpm",
"city_mpg", "highway_mpg", "price"
])
autos.head()
| symboling | normalized_losses | make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | wheel_base | ... | engine_size | fuel_system | bore | stroke | compression_ratio | horsepower | peak_rpm | city_mpg | highway_mpg | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | NaN | alfa-romero | gas | std | two | convertible | rwd | front | 88.6 | ... | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 13495.0 |
| 1 | 3 | NaN | alfa-romero | gas | std | two | convertible | rwd | front | 88.6 | ... | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 16500.0 |
| 2 | 1 | NaN | alfa-romero | gas | std | two | hatchback | rwd | front | 94.5 | ... | 152 | mpfi | 2.68 | 3.47 | 9.0 | 154.0 | 5000.0 | 19 | 26 | 16500.0 |
| 3 | 2 | 164.0 | audi | gas | std | four | sedan | fwd | front | 99.8 | ... | 109 | mpfi | 3.19 | 3.40 | 10.0 | 102.0 | 5500.0 | 24 | 30 | 13950.0 |
| 4 | 2 | 164.0 | audi | gas | std | four | sedan | 4wd | front | 99.4 | ... | 136 | mpfi | 3.19 | 3.40 | 8.0 | 115.0 | 5500.0 | 18 | 22 | 17450.0 |
5 rows × 26 columns
There are some obvious examples here for categorical types; for example make, body_style, drive_wheels, and engine_location. There are also some numeric columns that have been represented as words. Let’s fix those first. First we should see what possible values they can take:
autos['num_cylinders'].unique()
array(['four', 'six', 'five', 'three', 'twelve', 'two', 'eight'], dtype=object)
autos['num_doors'].unique()
array(['two', 'four', nan], dtype=object)
Let’s fix the nan values for num_doors; four seems a reasonable default for the number of doors of a car:
autos = autos.fillna({"num_doors": "four"})
To convert these to numbers we need to way to map from the number name to its value. We can use a dictionary for that:
numbers = {"two": 2, "three": 3, "four": 4, "five": 5, "six": 6, "eight": 8, "twelve": 12}
Now we can use the replace method to transform the values using the dictionary:
autos = autos.replace({"num_doors": numbers, "num_cylinders": numbers})
autos.head()
| symboling | normalized_losses | make | fuel_type | aspiration | num_doors | body_style | drive_wheels | engine_location | wheel_base | ... | engine_size | fuel_system | bore | stroke | compression_ratio | horsepower | peak_rpm | city_mpg | highway_mpg | price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | NaN | alfa-romero | gas | std | 2 | convertible | rwd | front | 88.6 | ... | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 13495.0 |
| 1 | 3 | NaN | alfa-romero | gas | std | 2 | convertible | rwd | front | 88.6 | ... | 130 | mpfi | 3.47 | 2.68 | 9.0 | 111.0 | 5000.0 | 21 | 27 | 16500.0 |
| 2 | 1 | NaN | alfa-romero | gas | std | 2 | hatchback | rwd | front | 94.5 | ... | 152 | mpfi | 2.68 | 3.47 | 9.0 | 154.0 | 5000.0 | 19 | 26 | 16500.0 |
| 3 | 2 | 164.0 | audi | gas | std | 4 | sedan | fwd | front | 99.8 | ... | 109 | mpfi | 3.19 | 3.40 | 10.0 | 102.0 | 5500.0 | 24 | 30 | 13950.0 |
| 4 | 2 | 164.0 | audi | gas | std | 4 | sedan | 4wd | front | 99.4 | ... | 136 | mpfi | 3.19 | 3.40 | 8.0 | 115.0 | 5500.0 | 18 | 22 | 17450.0 |
5 rows × 26 columns
Now let’s return to the categorical columns. We can use astype to convert the type, and we want to use the type category:
autos["make"] = autos["make"].astype('category')
autos["fuel_type"] = autos["fuel_type"].astype('category')
autos["aspiration"] = autos["aspiration"].astype('category')
autos["body_style"] = autos["body_style"].astype('category')
autos["drive_wheels"] = autos["drive_wheels"].astype('category')
autos["engine_location"] = autos["engine_location"].astype('category')
autos["engine_type"] = autos["engine_type"].astype('category')
autos["fuel_system"] = autos["fuel_system"].astype('category')
autos.dtypes
symboling int64
normalized_losses float64
make category
fuel_type category
aspiration category
num_doors int64
body_style category
drive_wheels category
engine_location category
wheel_base float64
length float64
width float64
height float64
curb_weight int64
engine_type category
num_cylinders int64
engine_size int64
fuel_system category
bore float64
stroke float64
compression_ratio float64
horsepower float64
peak_rpm float64
city_mpg int64
highway_mpg int64
price float64
dtype: object
Under the hood now each of these columns has been turned into a type similar to an enumeration. We can use the .cat attribute to access some of the details. For example, to see the numeric value’s now associated with each row for the make column:
autos['make'].cat.codes.head()
0 0
1 0
2 0
3 1
4 1
dtype: int8
autos['make'].cat.categories
Index(['alfa-romero', 'audi', 'bmw', 'chevrolet', 'dodge', 'honda', 'isuzu',
'jaguar', 'mazda', 'mercedes-benz', 'mercury', 'mitsubishi', 'nissan',
'peugot', 'plymouth', 'porsche', 'renault', 'saab', 'subaru', 'toyota',
'volkswagen', 'volvo'],
dtype='object')
autos['fuel_type'].cat.categories
Index(['diesel', 'gas'], dtype='object')
It’s possible to change the categories, assign new categories, remove category values, order or re-order the category values, and more; you can see more info at http://pandas.pydata.org/pandas-docs/stable/categorical.html
Having an underlying numerical representation is important; most machine learning algorithms require numeric features and can’t deal with strings or categorical symbolic values directly. For ordinal types we can usually just use the numeric encoding we have generated above, but with non-ordinal data we need to be careful; we shouldn’t be attributing weight to the underlying numeric values. Instead, for non-ordinal values, the typical approach is to use one-hot encoding - create a new column for each distinct value, and just use 0 or 1 in each of these columns to indicate if the observation is in that category. Let’s take a simple example:
wheels = autos[['make', 'drive_wheels']]
wheels.head()
| make | drive_wheels | |
|---|---|---|
| 0 | alfa-romero | rwd |
| 1 | alfa-romero | rwd |
| 2 | alfa-romero | rwd |
| 3 | audi | fwd |
| 4 | audi | 4wd |
The get_dummies method will 1-hot encode a feature:
onehot = pd.get_dummies(wheels['drive_wheels']).head()
onehot
| 4wd | fwd | rwd | |
|---|---|---|---|
| 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 |
| 3 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 |
To merge this into a dataframe with the make, we can merge with the wheels dataframe on the implicit index field, and then drop the original categorical column:
wheels.merge(onehot, left_index=True, right_index=True).drop('drive_wheels', axis=1)
| make | 4wd | fwd | rwd | |
|---|---|---|---|---|
| 0 | alfa-romero | 0 | 0 | 1 |
| 1 | alfa-romero | 0 | 0 | 1 |
| 2 | alfa-romero | 0 | 0 | 1 |
| 3 | audi | 0 | 1 | 0 |
| 4 | audi | 1 | 0 | 0 |
Aligned Operations
Pandas will align DataFrames on indexes when performing operations. Consider for example two DataFrames, one with number of transactions by day of week, and one with number of customers by day of week, and say we want to know average transactions per customer by date:
transactions = pd.DataFrame([2, 4, 5],
index=['Mon', 'Wed', 'Thu'])
customers = pd.DataFrame([2, 2, 3, 2],
index=['Sat', 'Mon', 'Tue', 'Thu'])
transactions / customers
| 0 | |
|---|---|
| Mon | 1.0 |
| Sat | NaN |
| Thu | 2.5 |
| Tue | NaN |
| Wed | NaN |
Notice how pandas aligned on index to produce the result, and used NaN for mismatched entries. We could specify the value to use as operands by using the div method:
transactions.div(customers, fill_value=0)
| 0 | |
|---|---|
| Mon | 1.000000 |
| Sat | 0.000000 |
| Thu | 2.500000 |
| Tue | 0.000000 |
| Wed | inf |
Chaining Methods and .pipe()
Many operations on Series and DataFrames return modified copies of the Series or Dataframe, unless the inplace=True argument is included. Even in that case there is usually a copy made and then the reference is just replaced at the end, so using inplace operations generally isn’t faster. Because a Series or Dataframe reference is returned, you can chain multiple operations, for example:
df = (pd.read_csv('data.csv')
.rename(columns=str.lower)
.drop('id', axis=1))
This is great for built-in operations, but what about custom operations? The good news is these are possible too, with .pipe(), which will allow you to specify your own functions to call as part of the operation chain:
def my_operation(df, *args, **kwargs):
# Do something to the df
...
# Return the modified dataframe
return df
# Now we can call this in our chain.
df = (pd.read_csv('data.csv')
.rename(columns=str.lower)
.drop('id', axis=1)
.pipe(my_operation, 'foo', bar=True))
Statistical Significance and Hypothesis Testing
In exploring the data, we may come up with hypotheses about relationships between different values. We can get an indication of whether our hypothesis is correct or the relationship is coincidental using tests of statistical significance.
We may have a simple hypothesis, like “All X are Y”. For phenomena in the real world, we usually we can’t explore all possible X, and so we can’t usually prove all X are Y. To prove the opposite, on the other hand, only requires a single counter-example. The well-known illustration is the black swan: to prove that all swans are white you would have to find every swan that exists (and possibly that has ever existed and may ever exist) and check its color, but to prove not all swans are white you need to find just a single swan that is not white and you can stop there. For these kinds of hypotheses we can often just look at our historical data and try to find a counterexample.
Let’s say that the conversion is better in the test set. How do we know that the change caused the improvement, and it wasn’t just by chance? One way is to combine the observations from both the test and control set, then take random samples, and see what the probability is of a sample showing a similar improvement in conversion. If the probability of a similar improvement from a random sample is very low, then we can conclude that the improvement from the change is statistically significant.
In practice we may have a large number of observations in the test set and a large number of observations in the control set, and the approach outlined above may be computationally too costly. There are various tests that can give us similar measures at a much lower cost, such as the t-test (when comparing means of populations) or the chi-squared test (when comparing categorical data). The details of how these tests work tests and which ones to choose are beyond the scope of this notebook.
The usual approach is to assume the opposite of what we want to prove; this is called the null hypothesis or \(H_0\). For our example, the null hypothesis states there is no relationship between our change and conversion on the website. We then calculate the probability that the data supports the null hypothesis rather than just being the result of unrelated variance: this is called the p-value. In general, a p-value of less than 0.05 (5%) is taken to mean that the hypothesis is valid, although this has recently become a contentious point. We’ll set aside that debate for now and stick with 0.05.
Let’s revisit the Titanic data:
import seaborn as sns;
titanic = sns.load_dataset('titanic')
titanic.head()
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
If we want to see how gender affected survival rates, one way is with cross-tabulation:
ct = pd.crosstab(titanic['survived'],titanic['sex'])
ct
| sex | female | male |
|---|---|---|
| survived | ||
| 0 | 81 | 468 |
| 1 | 233 | 109 |
There were a lot more men than women on the ship, and it certainly looks like the survival rate for women was better than for men, but is the difference statistically significant? Our hypothesis is that gender affects survivability, and so the null hypothesis is that it doesn’t. Let’s measure this with a chi-squared test:
from scipy import stats
chi2, p, dof, expected = stats.chi2_contingency(ct.values)
p
1.1973570627755645e-58
That’s a very small p-value! So we can be sure gender was an issue.
When running an online experiment, check the p-value periodically and plot the trend. You want to see the p-value gradually converging. If instead it is erratic and showing no sign of conversion, that suggests the experiment is not going to be conclusive.
One last comment: it is often said “correlation does not imply causation”. We should be more precise and less flippant than this! If X and Y are correlated, there are only four possibilities:
- this was a chance event. We can determine the probability of that and assess if its a reasonable explanation.
- X causes Y or Y causes X
- X and Y are both caused by some unknown factor Z. This is usually what we are referring to when saying “correlation does not imply causation”, but there is still causation!
Plotting
Pandas includes the ability to do simple plots. For a Series, this typically means plotting the values in the series as the Y values, and then index as the X values; for a DataFrame this would be a multiplot. You can use x and y named arguments to select specific columns to plot, and you can use a kind argument to specify the type of plot.
See https://pandas.pydata.org/pandas-docs/stable/visualization.html for details.
s = pd.Series([2, 3, 1, 5, 3], index=['a', 'b', 'c', 'd', 'e'])
s.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1a11adf4e0>
s.plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x1a125c2b00>
df = pd.DataFrame(
[
[2, 1],
[4, 4],
[1, 2],
[3, 6]
],
index=['a', 'b', 'c', 'd'],
columns=['s1', 's2']
)
df.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1a1b3b9438>
df.plot(x='s1', y='s2', kind='scatter')
<matplotlib.axes._subplots.AxesSubplot at 0x1a1b3dbf60>
Charting with Seaborn
See the Python Graph Gallery for many examples of different types of charts including the code used to create them. As you learn to use the plotting libraries in many cases the fastest way to get results is just find an example from there and copy/paste/edit it.
There are a number of plotting libraries for Python; the most well known are matplotlib, Seaborn, Bokeh, and Plotly. Some offer more interactivity than others. Matplotlib is the most commonly used; it is very flexible but requires a fair amount of boilerplate code. There is a good tutorial on matplotlib here. We will instead use Seaborn, which is built on top of matplotlib and simplifies its usage so that many plots just take one line of code.
# Let's get the more detailed Titanic data set
titanic3 = pd.read_excel('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.xls')
titanic3.head()
| pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked | boat | body | home.dest | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0 | 0 | 24160 | 211.3375 | B5 | S | 2 | NaN | St Louis, MO |
| 1 | 1 | 1 | Allison, Master. Hudson Trevor | male | 0.9167 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | 11 | NaN | Montreal, PQ / Chesterville, ON |
| 2 | 1 | 0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
| 3 | 1 | 0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | 135.0 | Montreal, PQ / Chesterville, ON |
| 4 | 1 | 0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1 | 2 | 113781 | 151.5500 | C22 C26 | S | NaN | NaN | Montreal, PQ / Chesterville, ON |
# We can use a factorplot to count categorical data
import seaborn as sns
sns.factorplot('sex', data=titanic3, kind='count')
<seaborn.axisgrid.FacetGrid at 0x1a1b596f98>
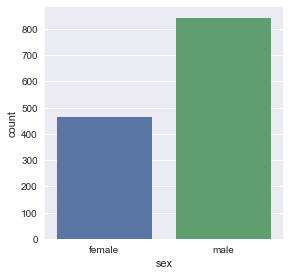
# Let's bring class in too:
sns.factorplot('pclass', data=titanic3, hue='sex', kind='count')
<seaborn.axisgrid.FacetGrid at 0x1a1b313fd0>
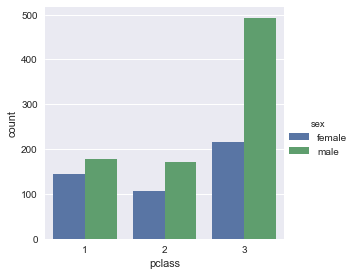
# Of course we can aggregate the other way too
sns.factorplot('sex', data=titanic3, hue='pclass', kind='count')
<seaborn.axisgrid.FacetGrid at 0x1a1b567a90>
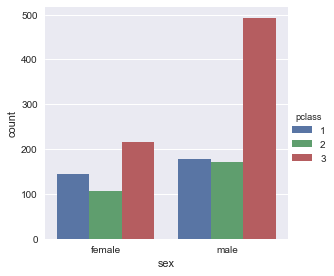
# Let's see how many people were on each deck
deck = pd.DataFrame(titanic3['cabin'].dropna().str[0])
deck.columns = ['deck'] # Get just the deck column
sns.factorplot('deck', data=deck, kind='count')
<seaborn.axisgrid.FacetGrid at 0x1a1b86fa58>
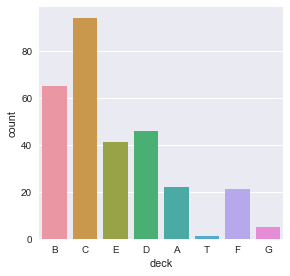
# What class passenger was on each deck?
df = titanic3[['cabin', 'pclass']].dropna()
df['deck'] = df.apply(lambda row: ord(row.cabin[0]) -64, axis=1)
sns.regplot(x=df["pclass"], y=df["deck"])
<matplotlib.axes._subplots.AxesSubplot at 0x1a11e88ba8>
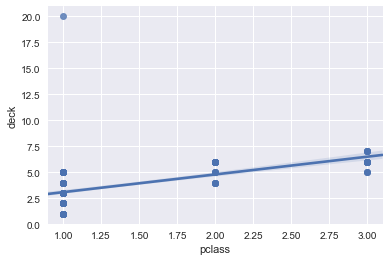
Working with Dates and Time Series
Pandas provides several classes for dealing with datetimes: Timestamp, Period, and Timedelta, and corresponding index types based off these, namely DatetimeIndex, PeriodIndex and TimedeltaIndex.
For parsing dates we can use pd.to_datetime which can parse dates in many formats, or pd.to_timedelta to get a time delta. For formatting dates as strings the Timestamp.strftime method can be used.
For example, to get a four-week-long range of dates starting from Christmas 2017:
di = pd.to_datetime("December 25, 2017") + pd.to_timedelta(np.arange(4*7), 'D')
di
DatetimeIndex(['2017-12-25', '2017-12-26', '2017-12-27', '2017-12-28',
'2017-12-29', '2017-12-30', '2017-12-31', '2018-01-01',
'2018-01-02', '2018-01-03', '2018-01-04', '2018-01-05',
'2018-01-06', '2018-01-07', '2018-01-08', '2018-01-09',
'2018-01-10', '2018-01-11', '2018-01-12', '2018-01-13',
'2018-01-14', '2018-01-15', '2018-01-16', '2018-01-17',
'2018-01-18', '2018-01-19', '2018-01-20', '2018-01-21'],
dtype='datetime64[ns]', freq=None)
It’s also possible to pass a list of dates to to_datetime to create a DatetimeIndex. A DatetimeIndex can be converted to a TimedeltaIndex by subtracting a start date:
di - di[0]
TimedeltaIndex([ '0 days', '1 days', '2 days', '3 days', '4 days',
'5 days', '6 days', '7 days', '8 days', '9 days',
'10 days', '11 days', '12 days', '13 days', '14 days',
'15 days', '16 days', '17 days', '18 days', '19 days',
'20 days', '21 days', '22 days', '23 days', '24 days',
'25 days', '26 days', '27 days'],
dtype='timedelta64[ns]', freq=None)
And of course the converse is possible:
(di - di[0]) + di[-1]
DatetimeIndex(['2018-01-21', '2018-01-22', '2018-01-23', '2018-01-24',
'2018-01-25', '2018-01-26', '2018-01-27', '2018-01-28',
'2018-01-29', '2018-01-30', '2018-01-31', '2018-02-01',
'2018-02-02', '2018-02-03', '2018-02-04', '2018-02-05',
'2018-02-06', '2018-02-07', '2018-02-08', '2018-02-09',
'2018-02-10', '2018-02-11', '2018-02-12', '2018-02-13',
'2018-02-14', '2018-02-15', '2018-02-16', '2018-02-17'],
dtype='datetime64[ns]', freq=None)
Another way of creating the indices is to specify range start and ends plus optionally the granularity, via the periods and freq arguments, using the APIs pd.date_range, pd.timedelta_range, and pd.interval_range:
pd.date_range('2017-12-30', '2017-12-31')
DatetimeIndex(['2017-12-30', '2017-12-31'], dtype='datetime64[ns]', freq='D')
pd.date_range('2017-12-30', '2017-12-31', freq='h') # Hourly frequency
DatetimeIndex(['2017-12-30 00:00:00', '2017-12-30 01:00:00',
'2017-12-30 02:00:00', '2017-12-30 03:00:00',
'2017-12-30 04:00:00', '2017-12-30 05:00:00',
'2017-12-30 06:00:00', '2017-12-30 07:00:00',
'2017-12-30 08:00:00', '2017-12-30 09:00:00',
'2017-12-30 10:00:00', '2017-12-30 11:00:00',
'2017-12-30 12:00:00', '2017-12-30 13:00:00',
'2017-12-30 14:00:00', '2017-12-30 15:00:00',
'2017-12-30 16:00:00', '2017-12-30 17:00:00',
'2017-12-30 18:00:00', '2017-12-30 19:00:00',
'2017-12-30 20:00:00', '2017-12-30 21:00:00',
'2017-12-30 22:00:00', '2017-12-30 23:00:00',
'2017-12-31 00:00:00'],
dtype='datetime64[ns]', freq='H')
pd.date_range('2017-12-30', periods=4) # 4 values using the default frequency of day
DatetimeIndex(['2017-12-30', '2017-12-31', '2018-01-01', '2018-01-02'], dtype='datetime64[ns]', freq='D')
pd.date_range('2017-12-30', periods=4, freq='h') # 4 values using hourly frequency
DatetimeIndex(['2017-12-30 00:00:00', '2017-12-30 01:00:00',
'2017-12-30 02:00:00', '2017-12-30 03:00:00'],
dtype='datetime64[ns]', freq='H')
Periods represent time intervals locked to timestamps. Consider the difference below:
pd.date_range('2017-01', '2017-12', freq='M') # This gives us 12 dates, one for each month, on the last day of each month
DatetimeIndex(['2017-01-31', '2017-02-28', '2017-03-31', '2017-04-30',
'2017-05-31', '2017-06-30', '2017-07-31', '2017-08-31',
'2017-09-30', '2017-10-31', '2017-11-30'],
dtype='datetime64[ns]', freq='M')
pd.period_range('2017-01', '2017-12', freq='M') # This gives us 12 month long periods
PeriodIndex(['2017-01', '2017-02', '2017-03', '2017-04', '2017-05', '2017-06',
'2017-07', '2017-08', '2017-09', '2017-10', '2017-11', '2017-12'],
dtype='period[M]', freq='M')
You may wonder why the dates above were on the last day of each month. Pandas uses frequency codes, as follows:
| Code | Meaning |
|---|---|
| D | Calendar day |
| B | Business day |
| W | Weekly |
| MS | Month start |
| BMS | Business month start |
| M | Month end |
| BM | Business month end |
| QS | Quarter start |
| BQS | Business quarter start |
| Q | Quarter end |
| BQ | Business quarter end |
| AS | Year start |
| A | Year end |
| BAS | Business year start |
| BS | Business year end |
| T | Minutes |
| S | Seconds |
| L | Milliseonds |
| U | Microseconds |
These can also be combined in some cases; e.g. “!H30T” or “90T” each represent 90 minutes:
pd.date_range('2017-01', periods=16, freq='1H30T')
DatetimeIndex(['2017-01-01 00:00:00', '2017-01-01 01:30:00',
'2017-01-01 03:00:00', '2017-01-01 04:30:00',
'2017-01-01 06:00:00', '2017-01-01 07:30:00',
'2017-01-01 09:00:00', '2017-01-01 10:30:00',
'2017-01-01 12:00:00', '2017-01-01 13:30:00',
'2017-01-01 15:00:00', '2017-01-01 16:30:00',
'2017-01-01 18:00:00', '2017-01-01 19:30:00',
'2017-01-01 21:00:00', '2017-01-01 22:30:00'],
dtype='datetime64[ns]', freq='90T')
We can also add month offsets to annual or quarterly frequencies or day of week constraints to weekly frequencies:
pd.date_range('2017', periods=4, freq='QS-FEB') # 4 quarters starting from beginning of February
DatetimeIndex(['2017-02-01', '2017-05-01', '2017-08-01', '2017-11-01'], dtype='datetime64[ns]', freq='QS-FEB')
pd.date_range('2017-01', periods=4, freq='W-MON') # First 4 Mondays in Jan 2017
DatetimeIndex(['2017-01-02', '2017-01-09', '2017-01-16', '2017-01-23'], dtype='datetime64[ns]', freq='W-MON')
So what use are all these? To understand that we need some time-series data. Let’s get the eBay daily stock closing price for 2017:
import sys
!conda install --yes --prefix {sys.prefix} pandas-datareader
Solving environment: done
# All requested packages already installed.
from pandas_datareader import data
ebay = data.DataReader('EBAY', start='2017', end='2018', data_source='iex')['close']
ebay.plot()
2y
<matplotlib.axes._subplots.AxesSubplot at 0x1a1c3bd7f0>
ebay.head()
date
2017-01-03 29.84
2017-01-04 29.76
2017-01-05 30.01
2017-01-06 31.05
2017-01-09 30.75
Name: close, dtype: float64
ebay.index
Index(['2017-01-03', '2017-01-04', '2017-01-05', '2017-01-06', '2017-01-09',
'2017-01-10', '2017-01-11', '2017-01-12', '2017-01-13', '2017-01-17',
...
'2017-12-15', '2017-12-18', '2017-12-19', '2017-12-20', '2017-12-21',
'2017-12-22', '2017-12-26', '2017-12-27', '2017-12-28', '2017-12-29'],
dtype='object', name='date', length=251)
Our index is not timestamp-based, so let’s fix that:
ebay.index = pd.to_datetime(ebay.index)
ebay.index
DatetimeIndex(['2017-01-03', '2017-01-04', '2017-01-05', '2017-01-06',
'2017-01-09', '2017-01-10', '2017-01-11', '2017-01-12',
'2017-01-13', '2017-01-17',
...
'2017-12-15', '2017-12-18', '2017-12-19', '2017-12-20',
'2017-12-21', '2017-12-22', '2017-12-26', '2017-12-27',
'2017-12-28', '2017-12-29'],
dtype='datetime64[ns]', name='date', length=251, freq=None)
Let’s plot just January prices:
ebay["2017-01"].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1a1c3d9470>
Let’s plot weekly closing prices:
ebay[pd.date_range('2017-01', periods=52, freq='W-FRI')].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1a1c3d9630>
This is just a small sample of what Pandas can do with time series; Pandas came out of financial computation and has very rich capabilities in this area.
Summarizing Data with pandas_profiling and facets
pandas_profiling is a Python package that can produce much more detailed summaries of data than the .describe() method. In this case we must install with pip and the right way to do this from the notebook is:
import sys
!{sys.executable} -m pip install pandas-profiling
%matplotlib inline
import pandas_profiling
import seaborn as sns;
titanic = sns.load_dataset('titanic')
pandas_profiling.ProfileReport(titanic) # You may need to run cell twice
Overview
Dataset info
| Number of variables | 15 |
|---|---|
| Number of observations | 891 |
| Total Missing (%) | 6.5% |
| Total size in memory | 80.6 KiB |
| Average record size in memory | 92.6 B |
Variables types
| Numeric | 5 |
|---|---|
| Categorical | 7 |
| Boolean | 3 |
| Date | 0 |
| Text (Unique) | 0 |
| Rejected | 0 |
| Unsupported | 0 |
<p class="h4">Warnings</p>
<ul class="list-unstyled"><li><a href="#pp_var_age"><code>age</code></a> has 177 / 19.9% missing values <span class="label label-default">Missing</span></li><li><a href="#pp_var_deck"><code>deck</code></a> has 688 / 77.2% missing values <span class="label label-default">Missing</span></li><li><a href="#pp_var_fare"><code>fare</code></a> has 15 / 1.7% zeros <span class="label label-info">Zeros</span></li><li><a href="#pp_var_parch"><code>parch</code></a> has 678 / 76.1% zeros <span class="label label-info">Zeros</span></li><li><a href="#pp_var_sibsp"><code>sibsp</code></a> has 608 / 68.2% zeros <span class="label label-info">Zeros</span></li><li>Dataset has 107 duplicate rows <span class="label label-warning">Warning</span></li> </ul>
</div>
Variables
adult_male
Boolean
| Distinct count | 2 |
|---|---|
| Unique (%) | 0.2% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Mean | 0.60269 |
|---|
| True | |
|---|---|
| (Missing) | |
| Value | Count | Frequency (%) | |
| True | 537 | 60.3% | |
| (Missing) | 354 | 39.7% |
age
Numeric
| Distinct count | 89 |
|---|---|
| Unique (%) | 10.0% |
| Missing (%) | 19.9% |
| Missing (n) | 177 |
| Infinite (%) | 0.0% |
| Infinite (n) | 0 |
</div>
<div class="col-sm-6">
<table class="stats ">
<tr>
<th>Mean</th>
<td>29.699</td>
</tr>
<tr>
<th>Minimum</th>
<td>0.42</td>
</tr>
<tr>
<th>Maximum</th>
<td>80</td>
</tr>
<tr class="ignore">
<th>Zeros (%)</th>
<td>0.0%</td>
</tr>
</table>
</div>
</div>

</ul>
<div class="tab-content">
<div role="tabpanel" class="tab-pane active row" id="quantiles-2520434146686720069">
<div class="col-md-4 col-md-offset-1">
<p class="h4">Quantile statistics</p>
<table class="stats indent">
<tr>
<th>Minimum</th>
<td>0.42</td>
</tr>
<tr>
<th>5-th percentile</th>
<td>4</td>
</tr>
<tr>
<th>Q1</th>
<td>20.125</td>
</tr>
<tr>
<th>Median</th>
<td>28</td>
</tr>
<tr>
<th>Q3</th>
<td>38</td>
</tr>
<tr>
<th>95-th percentile</th>
<td>56</td>
</tr>
<tr>
<th>Maximum</th>
<td>80</td>
</tr>
<tr>
<th>Range</th>
<td>79.58</td>
</tr>
<tr>
<th>Interquartile range</th>
<td>17.875</td>
</tr>
</table>
</div>
<div class="col-md-4 col-md-offset-2">
<p class="h4">Descriptive statistics</p>
<table class="stats indent">
<tr>
<th>Standard deviation</th>
<td>14.526</td>
</tr>
<tr>
<th>Coef of variation</th>
<td>0.48912</td>
</tr>
<tr>
<th>Kurtosis</th>
<td>0.17827</td>
</tr>
<tr>
<th>Mean</th>
<td>29.699</td>
</tr>
<tr>
<th>MAD</th>
<td>11.323</td>
</tr>
<tr class="">
<th>Skewness</th>
<td>0.38911</td>
</tr>
<tr>
<th>Sum</th>
<td>21205</td>
</tr>
<tr>
<th>Variance</th>
<td>211.02</td>
</tr>
<tr>
<th>Memory size</th>
<td>7.0 KiB</td>
</tr>
</table>
</div>
</div>
<div role="tabpanel" class="tab-pane col-md-8 col-md-offset-2" id="histogram-2520434146686720069">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAlgAAAGQCAYAAAByNR6YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD%2BnaQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAIABJREFUeJzt3XtwVPX9//FXkoVkkxhDhah1/BYVEo0JErmJRJGUFAEBi0ioQrVIbwRSkISCjl8QyoCVQcRQBUSnFKuRSqwKFGhHGEslAioiI5cgiBckK0EIISG38/vDr6v7CxYi72R3D8/HTCbmsHv282bPbp45u5EIx3EcAQAAwExksBcAAADgNgQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIx5gr2A84XPV2G2r8jICP3gB3EqL69UQ4Njtt9gc%2BtcErOFK2YLT26dza1zSc07W7t2F5ju72xxBisMRUZGKCIiQpGREcFeiim3ziUxW7hitvDk1tncOpfkztkILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADA2Hn/jz2Xl5crJydHf/jDH9SjRw/97//%2Br1599dWAy1RXV%2BvGG2/U0qVL1dDQoC5dushxHEVEfPNvJm3atEmxsbEtvXwAABCCzuvA2rZtm6ZMmaKDBw/6t82YMUMzZszwf/3vf/9bkyZN0pQpUyRJpaWlqq2t1dtvv63WrVu3%2BJoBAEDoO28Dq7i4WAsWLFBBQYEmTpx42suUl5crPz9fDz74oDp27ChJ2rFjh1JSUoir80D/%2BZuCvYQmWTOhV7CXAAD4P%2Bfte7AyMzO1fv16DRgw4DsvM3fuXKWlpWnw4MH%2BbTt27NCpU6d0xx136IYbbtDdd9%2Btt99%2BuyWWDAAAwsR5G1jt2rWTx/PdJ/A%2B/vhjvfLKK5o0aVLA9piYGHXq1El/%2BtOftGHDBmVlZem%2B%2B%2B7Txx9/3NxLBgAAYeK8fYnwTF566SVlZGTommuuCdj%2B9Xuxvnbfffdp5cqV2rhxo0aOHClJKisrk8/nC7icxxOrpKQkk7VFRUUGfHYLt87VUjye4Py9ufl%2BY7bw5NbZ3DqX5M7ZCKzvsG7dOo0ePbrR9scee0z9%2BvVTamqqf1tNTY2io6P9XxcVFamwsDDgerm5ucrLyzNdY0KC13R/ocKtczW3Nm3ignr7br7fmC08uXU2t84luWs2Aus0jh49qn379qlbt26N/mzPnj3aunWr5s%2BfrwsvvFCLFy/WiRMnlJ2d7b9MTk6OsrKyAq7n8cTq6NFKk/VFRUUqIcGr48erVF/fYLLPUODWuVqK1fHVVG6%2B35gtPLl1NrfOJTXvbMH64ZPAOo1PPvlEknTxxRc3%2BrPZs2frkUce0ZAhQ1RVVaX09HQ9%2B%2ByzSkxM9F8mKSmp0cuBPl%2BF6upsD5r6%2BgbzfYYCt87V3IL9d%2Bbm%2B43ZwpNbZ3PrXJK7ZiOwJO3evTvg6/T09EbbvpaYmKjZs2e3xLIAAECYcs%2B7yQAAAEIEgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMb43zQALtF//qZgL%2BGsrZnQK9hLAIBmxRksAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAWEgFVnl5ubKzs1VSUuLfNm3aNKWlpSkjI8P/UVRU5P/zJUuW6Oabb1bnzp01atQoffjhh8FYOgAAgF/IBNa2bduUk5OjgwcPBmzfsWOHZs6cqXfeecf/kZOTI0kqLi7WX/7yFy1dulQlJSW69tprlZeXJ8dxgjECAACApBAJrOLiYuXn52vixIkB22tqarRnzx6lpaWd9novvvii7rrrLnXs2FHR0dGaNGmSPvvss4AzYAAAAC0tJAIrMzNT69ev14ABAwK279q1S3V1dVqwYIFuvPFG9evXT4sXL1ZDQ4MkqbS0VMnJyf7Lt2rVSu3bt9euXbtadP0AAADf5gn2AiSpXbt2p91eUVGh7t27a9SoUZo3b54%2B%2BOAD5ebmKjIyUmPGjFFlZaW8Xm/AdWJiYnTy5MmWWPZ3Kisrk8/nC9jm8cQqKSnJZP9RUZEBn93CrXOhMY8nPO5jNx%2BTzBZ%2B3DqX5M7ZQiKwvkuvXr3Uq1cv/9edOnXSPffco9WrV2vMmDHyer2qrq4OuE51dbXi4uJaeqkBioqKVFhYGLAtNzdXeXl5preTkOA984XCkFvnwjfatAnuY7Sp3HxMMlv4cetckrtmC%2BnA%2Buc//6kvvvhCI0aM8G%2BrqalRTEyMJKljx47au3ev%2BvTpI0mqra3VgQMHAl42DIacnBxlZWUFbPN4YnX0aKXJ/qOiIpWQ4NXx41Wqr28w2WcocOtcaMzqsdDc3HxMMlv4cetcUvPOFqwf6EI6sBzH0ezZs/WjH/1IN9xwg959910tW7ZMU6dOlSTdcccdeuKJJ3TzzTfriiuu0GOPPaa2bduqa9euQV13UlJSo5cDfb4K1dXZHjT19Q3m%2BwwFbp0L3wi3%2B9fNxySzhR%2B3ziW5a7aQDqzs7GxNnTpV06dP1%2BHDh9W2bVuNHz9eQ4YMkSQNGzZMFRUVys3NVXl5udLT07Vo0SK1atUqyCsHAADns5ALrN27dwd8PWLEiICXCL8tIiJCo0eP1ujRo1tiaQAAAGfFPW/XBwAACBEEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAY64PrPLycmVnZ6ukpMS/be3atRoyZIiuv/56ZWVlqbCwUA0NDf4/79%2B/v6677jplZGT4P/bt2xeM5QMAgDDkCfYCmtO2bds0ZcoUHTx40L/t/fff1%2BTJkzV//nz17t1b%2B/fv1y9/%2BUvFxsZq9OjROnHihPbv369//etfuuyyy4K4egAAEK5cewaruLhY%2Bfn5mjhxYsD2Tz/9VCNGjFCfPn0UGRmpq666StnZ2dqyZYukrwIsMTGRuAIAAN%2BbawMrMzNT69ev14ABAwK29%2BvXT1OnTvV/XV1drQ0bNujaa6%2BVJO3YsUNer1cjR45Ujx49NHToUL3%2B%2BustunYAABDeXPsSYbt27c54mRMnTuh3v/udYmJidO%2B990qSIiIilJ6ervvvv18//OEP9Y9//EPjx4/X8uXL1blz57O67bKyMvl8voBtHk%2BskpKSmjzH6URFRQZ8dgu3zoXGPJ7wuI/dfEwyW/hx61ySO2dzbWCdyYcffqi8vDxddNFFWrZsmeLj4yVJY8aMCbjc4MGD9dprr2nt2rVnHVhFRUUqLCwM2Jabm6u8vDybxf%2BfhASv6f5ChVvnwjfatIkL9hKaxM3HJLOFH7fOJblrtvMysDZu3Kj7779fw4cP16RJk%2BTxfPPXsHTpUqWmpqpnz57%2BbTU1NYqOjj7r/efk5CgrKytgm8cTq6NHK8998fqq8BMSvDp%2BvEr19Q1nvkKYcOtcaMzqsdDc3HxMMlv4cetcUvPOFqwf6M67wHr33XeVm5ur6dOna9iwYY3%2B/NChQ1qxYoWWLFmiSy%2B9VC%2B//LLeeecdPfzww2d9G0lJSY1eDvT5KlRXZ3vQ1Nc3mO8zFLh1Lnwj3O5fNx%2BTzBZ%2B3DqX5K7ZzrvAeuqpp1RXV6dZs2Zp1qxZ/u1dunTR008/rcmTJysyMlJ33XWXKioq1KFDBy1evFg/%2BtGPgrhqAAAQTs6LwNq9e7f/v5966qn/etnWrVvrgQce0AMPPNDcywIAAC7lnrfrAwAAhAgCCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxs6L/w8WgNDSf/6mYC%2BhSdbn3xTsJQAIM5zBAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYCwsA6u8vFzZ2dkqKSnxbzt58qSmTp2qHj16qEuXLpo8ebIqKytbbE3FxcXKzs5W586dNXToUL3zzjstdtsAACC0hF1gbdu2TTk5OTp48GDA9pkzZ%2BrQoUNau3at1q1bp0OHDmnu3LktsqaSkhLNnDlTc%2BbM0ZYtWzR48GD99re/VVVVVYvcPgAACC1hFVjFxcXKz8/XxIkTA7ZXVVXp1VdfVV5enhITE3XRRRcpPz9fK1eubJHIWbFihQYOHKguXbqoVatWuvfee9WmTRutXr262W8bAACEnrAKrMzMTK1fv14DBgwI2P7RRx%2BptrZWycnJ/m1XXXWVqqurdeDAgWZfV2lpacBtS1KHDh20a9euZr9tAAAQejzBXkBTtGvX7rTbT5w4IUmKjY31b/N6vZLUIu/Dqqys9N/e12JiYnTy5Mlmv20AABB6wiqwvsvXYVVVVaW4uDj/f0tSfHx8s9%2B%2B1%2BtVdXW1/%2BuysjKVlZWpbdu22rlzpyTJ44lVUlKSye1FRUUGfHYLt86F8OfGY9LNjze3zubWuSR3zuaKwLriiivUqlUrlZaW6rrrrpMk7du3T61atVL79u2b/fY7duyovXv3%2Br8uKirS5s2bJUmvvfaaJCk3N1d5eXmmt5uQ4D3zhcKQW%2BdC%2BHLzMcls4cetc0nums0VgeX1etW/f3/NnTtXjz/%2BuCRp7ty5uu222xQTE9Pstz9s2DDl5uaqf//%2B6tKliyIiIhQfH6%2BFCxfqggsukPTVGayjR21eroyKilRCglfHj1epvr7BZJ%2BhwK1zIfy58Zh08%2BPNrbO5dS6peWdr0ybOdH9nyxWBJUnTpk3TI488okGDBqm2tlY//vGP9dBDD7XIbffs2VPTpk3T9OnTdfjwYXXo0EHPPPOM/2yaJPl8Faqrsz1o6usbzPcZCtw6F8KXm49JZgs/bp1LctdsEY7jOMFexPnA56sw25fHE6k2beJ09Gilaw5EKfTm6j9/U7CXgBCxPv%2BmkDgmLYXa482SW2dz61xS887Wrt0Fpvs7W%2B55NxkAAECIILAAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwJgn2Atwo7KyMvl8voBtHk%2BskpKSTPYfFRUZ8Nkt3DoXwp8bj0k3P97cOptb55LcORuB1QyKiopUWFgYsC03N1d5eXmmt5OQ4DXdX6hw61wIX24%2BJpkt/Lh1LsldsxFYzSAnJ0dZWVkB2zyeWB09Wmmy/6ioSCUkeHX8eJXq6xtM9hkK3DoXwp8bj0k3P97cOptb55Kad7Y2beJM93e2CKxmkJSU1OjlQJ%2BvQnV1tgdNfX2D%2BT5DgVvnQvhy8zHJbOHHrXNJ7prNPS92AgAAhAgCCwAAwBiBBQAAYIzAAgAAMEZgAQAAGOO3CAHgDLLnvhHsJTTJmgm9gr0E4LzHGSwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMCYJ9gLwLnpP39TsJdw1tZM6BXsJQAA0CI4g/U9rF69WqmpqcrIyPB/FBQUSJI2btyoQYMGqXPnzurfv79ef/31IK8WAAC0NM5gfQ87duzQkCFDNHv27IDtBw4c0Pjx4zVv3jzdcsstWrdunSZMmKB169YpMjI2SKsFAAAtjTNY38OOHTuUlpbWaHtxcbG6du2qvn37yuPxaMCAAerWrZuKioqCsEoAABAsnMFqooaGBu3cuVNer1dPP/206uvr1bt3b%2BXn56u0tFTJyckBl%2B/QoYN27doVpNUCAIBg4AxWE5WXlys1NVX9%2BvXT6tWr9cILL%2BjAgQMqKChQZWWlvF5vwOVjYmJ08uTJIK0WAAAEA2ewmqht27Z67rnn/F97vV4VFBRo%2BPDh6tGjh6qrq1VWViafzydJ%2BuSTT1RfX6/y8i%2BUlJRksoaoqMiAz%2BHC4/nv6w3XuYBQc6bHmuTux5tbZ3PrXJI7ZyOwmmjXrl167bXXNGnSJEVEREiSampqFBkZqU6dOumDDz5QUVGRCgsLA663du2rysvLM11LQoL3zBcKIW3axJ3V5cJtLiDUnO1jTXL3482ts7l1LsldsxFYTZSYmKjnnntOF154oX7xi1%2BorKxMjz76qH7605/q9ttv15///Gf17dtXK1as0ObNm/XEE09o3rx5%2Bp//6aCjRytN1hAVFamEBK%2BOH68y2V9LOdP8356rvr6hhVYFuM/ZPNe4%2BfHm1tncOpfUvLM15QcOSwRWE11yySVatGiR5s2bpyeffFLR0dEaOHCgCgoKFB0drYULF2ru3Lk6ePCgLrvsMhUWFqp3797y%2BSpUV2d70ITbA%2Bxs56%2BvbzD/uwLOJ015/Lj58ebW2dw6l%2BSu2Qis76F79%2B564YUXTvtnN910k2666aYWXhEAAAgl7nk3GQAAQIggsAAAAIwRWAAAAMZ4DxZaTP/5m4K9BAAAWgRnsAAAAIxxBgsAXCaczhavmdAr2EsAmgVnsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGPMEewFuVFZWJp/PF7DN44lVUlKSyf6joiIDPgNAuPJ47J/H3Poc6da5JHfORmA1g6KiIhUWFgZsy83NVV5enuntJCR4TfcHAC2tTZu4Ztu3W58j3TqX5K7ZCKxmkJOTo6ysrIBtHk%2Bsjh6tNNl/VFSkEhK8On68ymR/ABAsVs%2BL3/bt58j6%2Bgbz/QeLW%2BeSmne25oz4/4bAagZJSUmNXg70%2BSpUV2d70LjtAQbg/JM9941gL6FJ1kzoFewlqL6%2Bwfz7Sahw02zuebETAAAgRBBYAAAAxggsAAAAYwQWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjHmCvQAAAMJF//mbgr2EJlkzoVewl3De4gwWAACAMQILAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAADGCCwAAABjBBYAAIAxAgsAAMAYgQUAAGCMf4sQAACXCqd/O3HrrFuDvQRTnMECAAAwxhmsZlBWViafzxewzeOJVVJSksn%2Bo6IiAz4DAOAGbvq%2BFuE4jhPsRbjNE088ocLCwoBt48aN0/jx4032X1ZWpqKiIuXk5JhFWyhw61wSs4UrZgtPbp3NrXNJ7pzNPakYQnJycrRy5cqAj5ycHLP9%2B3w%2BFRYWNjpLFu7cOpfEbOGK2cKTW2dz61ySO2fjJcJmkJSU5JoCBwAATccZLAAAAGMEFgAAgLGo6dOnTw/2ItB0cXFx6t69u%2BLi4oK9FFNunUtitnDFbOHJrbO5dS7JfbPxW4QAAADGeIkQAADAGIEFAABgjMACAAAwRmABAAAYI7AAAACMEVgAAOC89t577%2BnWW2%2BVJE2ePFnLly8/530SWAAA4LxWVVWl/fv3S5IOHTqko0ePnvM%2BCSwAAABjBBaaxZEjRzR27Fh17dpVPXr00KxZs1RXV9focuXl5crOzlZJSYl/2/bt23XnnXcqIyNDWVlZWrFiRUsuHd/hs88%2B01133aXU1FSlpKQoPT1dkydPVnV1tSRpzZo1uv7665WSkqJrrrlG48aNC/KK7ZWVlenGG2/UypUrg72U09q/f7/uueceZWRkKDMzU0899ZRWr16t1NRUZWRk%2BD8KCgqCvVQTX375pSZPnqwePXqoW7duGjt2rMrKyiSF9/PIK6%2B8EnB/ZWRkKC0tTWlpacFeWpNt3LhRgwYNUufOndW/f3%2B9/vrrwV5Sy3GAZjBy5Ehn0qRJzsmTJ52DBw86AwcOdJYsWRJwma1btzp9%2B/Z1kpOTnc2bNzuO4zhffvml0717d2f58uVObW2t85///MfJyMhwtm/fHowx8C233Xabc/XVVzvPP/%2B8c/z4cWfChAlOWlqa8/jjjzs%2Bn8%2B5%2BuqrnXvvvdeprKx0nn/%2BeSclJcV58skng71sM/X19c6oUaOcq6%2B%2B2nnppZeCvZxGampqnJ/85CfOo48%2B6pw6dcrZuXOnk5mZ6fz61792pkyZEuzlNYuRI0c6ubm5zrFjx5yKigpn3Lhxzq9%2B9SvXPY98/vnnTq9evZyXX3452Etpkv379zvp6enO%2BvXrndraWmfVqlVOp06dnM8//zzYS2tk8%2BbNTnJysuM4Xx1XCxYsOOd9cgYL5j766CO99dZbKigokNfr1eWXX66xY8fqueee81%2BmuLhY%2Bfn5mjhxYsB1161bp8TERN19993yeDzq2bOnBg0aFHBdtLxjx44pKSlJa9as0YgRIxQfH69bb71VNTU18nq9WrJkiRzH0aJFixQbG6sRI0aoU6dOWrZsWbCXbmbhwoW65JJLdOmllwZ7Kae1ZcsWlZWVKS8vT61bt1ZqaqpGjRqlrVu3huWZjzN5//33tX37ds2ZM0cJCQmKj4/XzJkzlZ%2Bf76rnEcdxVFBQoFtuuUVDhgwJ9nKapLi4WF27dlXfvn3l8Xg0YMAAdevWTUVFRcFeWosgsGBu7969SkxM1MUXX%2BzfdtVVV%2Bmzzz7T8ePHJUmZmZlav369BgwY0Oi6ycnJAds6dOigXbt2Nf/C8Z0uvPBCLV26VO3bt5ck9e7d2/%2BN/O6779bOnTsVHx%2Bv1q1b%2B6%2BTkpJi8kbRULB582atWrVK06ZNC/ZSvtPevXt1xRVXBNwHV155pSoqKrRhwwb16dNHN998sx566CEdO3YsiCu18d5776lDhw568cUXlZ2drczMTD3yyCNq166dq55H/v73v6u0tFRTpkwJ9lKarLS01DX3w/dBYMFcZWWlvF5vwLavvz558qQkqV27dvJ4PGd13ZiYGP/1EBrGjBmj6OhoXXnllcrLy9PJkycDvrFLUlxcnBoaGoK0QjtHjhzRAw88oLlz5youLi7Yy/lOp3vsfP2%2Bx379%2Bmn16tV64YUXdODAAVe8B%2BvYsWPavXu3Dhw4oOLiYr388ss6fPiwfv/737vmeaShoUFPPvmkfvOb3yg%2BPj7Yy2myUL8fli9frvT0dKWnp%2Bu%2B%2B%2B4z33/j73DAOYqNjVVVVVXAtq%2B/PtM3KK/Xq4qKioBt1dXVIf2N7XxSU1Oj2bNna/Xq1Vq8eLFiY2N15513qmvXrqqtrQ24bGVlpSIjw/tnOMdxNHnyZI0aNSrkX2Y73eOudevWSkhI0LBhwyR99fgqKCjQ8OHDdeLEibD8pv21r4P%2BwQcfVHR0tOLj4zVhwgQNHz5cQ4cO9f/yxdfC8XmkpKREZWVl/vsv3Hi93pC%2BHwYNGqSePXs22/4JLJjr2LGjvvzyS33xxRdq27atJGnfvn265JJLdMEFF/zX6yYnJ2vTpk0B20pLS9WxY8dmWy/OzoYNG5SXl6crr7xSf/vb33T55Zdr69atatWqlVJTU7Vt2zbV1dX5z0zu3r1biYmJQV71uTl06JDeeustbd%2B%2BXQsXLpQknThxQg8//LDWrl2rRYsWBXmF3%2BjYsaMOHDgQcB%2B8%2Beab8nq9chxHERERkr6K5MjIyEZnHMNNhw4d1NDQoNraWkVHR0uS/4zpNddco7/%2B9a8Blw/H55G1a9cqOztbsbGxwV7K95KcnKydO3cGbCstLQ2ZH1beeOMNPfPMM42279%2B/X927dz/3Gzjnt8kDp/Gzn/3MmThxolNRUeH/LcLv%2Bq2Mb/8WYXl5udO1a1fn2WefdWpqapw333zTycjIcN58882WXD7%2BPzU1Nc7gwYOd9PR0Z8aMGc6pU6ecTz75xBk2bJgzbdo0x%2BfzOSkpKc6oUaOciooKp6irUSPGAAACBklEQVSoyElJSXH%2B%2BMc/Bnvp5vr06ROSv0VYW1vrZGVlOXPmzHGqq6udDz74wOnZs6eTlpbmLF682KmtrXU%2B/fRTZ/jw4c4DDzwQ7OWes5qaGic7O9sZP368c%2BLECefIkSPOz3/%2Bcyc3N9c1zyO33Xab8%2BKLLwZ7Gd9baWmpk56e7qxatcr/W4Tp6enOhx9%2BGOylOY7z1W%2Btl5aWnvbjyJEj57z/CMdxnHPPNCDQF198oRkzZqikpESRkZG6/fbblZ%2Bfr6ioqEaXTUlJ0bJly9SjRw9J0o4dOzRr1izt2bNHP/jBDzR27FgNHTq0pUfAt6xbt07jx49Xq1atVF9fr4aGBkVERCgqKkqrVq1S%2B/bttX79ek2dOlUVFRWKiopS3759tWDBgmAv3VxWVpbGjRsXksfkRx99pBkzZmj79u2KjY3VyJEj1blzZ82bN0979uxRdHS0Bg4cqIKCAv9Zn3B2%2BPBhzZkzR1u2bNGpU6eUlZWlBx98UAkJCa54HsnIyND8%2BfPVu3fvYC/le3vjjTc0d%2B5cHTx4UJdddpkKCgrCep6mILAAAACMhfc7UAEAAEIQgQUAAGCMwAIAADBGYAEAABgjsAAAAIwRWAAAAMYILAAAAGMEFgAAgDECCwAAwBiBBQAAYIzAAgAAMEZgAQAAGCOwAAAAjBFYAAAAxggsAAAAY/8PKcmgN6fM1k4AAAAASUVORK5CYII%3D"/>
</div>
<div role="tabpanel" class="tab-pane col-md-12" id="common-2520434146686720069">
| Value | Count | Frequency (%) | |
| 24.0 | 30 | 3.4% | |
| 22.0 | 27 | 3.0% | |
| 18.0 | 26 | 2.9% | |
| 28.0 | 25 | 2.8% | |
| 19.0 | 25 | 2.8% | |
| 30.0 | 25 | 2.8% | |
| 21.0 | 24 | 2.7% | |
| 25.0 | 23 | 2.6% | |
| 36.0 | 22 | 2.5% | |
| 29.0 | 20 | 2.2% | |
| Other values (78) | 467 | 52.4% | |
| (Missing) | 177 | 19.9% |
Minimum 5 values
| Value | Count | Frequency (%) | |
| 0.42 | 1 | 0.1% | |
| 0.67 | 1 | 0.1% | |
| 0.75 | 2 | 0.2% | |
| 0.83 | 2 | 0.2% | |
| 0.92 | 1 | 0.1% |
Maximum 5 values
| Value | Count | Frequency (%) | |
| 70.0 | 2 | 0.2% | |
| 70.5 | 1 | 0.1% | |
| 71.0 | 2 | 0.2% | |
| 74.0 | 1 | 0.1% | |
| 80.0 | 1 | 0.1% |
alive
Categorical
| Distinct count | 2 |
|---|---|
| Unique (%) | 0.2% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| no | |
|---|---|
| yes | |
| Value | Count | Frequency (%) | |
| no | 549 | 61.6% | |
| yes | 342 | 38.4% |
alone
Boolean
| Distinct count | 2 |
|---|---|
| Unique (%) | 0.2% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Mean | 0.60269 |
|---|
| True | |
|---|---|
| (Missing) | |
| Value | Count | Frequency (%) | |
| True | 537 | 60.3% | |
| (Missing) | 354 | 39.7% |
class
Categorical
| Distinct count | 3 |
|---|---|
| Unique (%) | 0.3% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Third | |
|---|---|
| First | |
| Second | |
| Value | Count | Frequency (%) | |
| Third | 491 | 55.1% | |
| First | 216 | 24.2% | |
| Second | 184 | 20.7% |
deck
Categorical
| Distinct count | 8 |
|---|---|
| Unique (%) | 0.9% |
| Missing (%) | 77.2% |
| Missing (n) | 688 |
| C | 59 |
|---|---|
| B | 47 |
| D | 33 |
| Other values (4) | 64 |
| (Missing) | |
| Value | Count | Frequency (%) | |
| C | 59 | 6.6% | |
| B | 47 | 5.3% | |
| D | 33 | 3.7% | |
| E | 32 | 3.6% | |
| A | 15 | 1.7% | |
| F | 13 | 1.5% | |
| G | 4 | 0.4% | |
| (Missing) | 688 | 77.2% |
embark_town
Categorical
| Distinct count | 4 |
|---|---|
| Unique (%) | 0.4% |
| Missing (%) | 0.2% |
| Missing (n) | 2 |
| Southampton | |
|---|---|
| Cherbourg | |
| Queenstown | 77 |
| (Missing) | 2 |
| Value | Count | Frequency (%) | |
| Southampton | 644 | 72.3% | |
| Cherbourg | 168 | 18.9% | |
| Queenstown | 77 | 8.6% | |
| (Missing) | 2 | 0.2% |
embarked
Categorical
| Distinct count | 4 |
|---|---|
| Unique (%) | 0.4% |
| Missing (%) | 0.2% |
| Missing (n) | 2 |
| S | |
|---|---|
| C | |
| Q | 77 |
| (Missing) | 2 |
| Value | Count | Frequency (%) | |
| S | 644 | 72.3% | |
| C | 168 | 18.9% | |
| Q | 77 | 8.6% | |
| (Missing) | 2 | 0.2% |
fare
Numeric
| Distinct count | 248 |
|---|---|
| Unique (%) | 27.8% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Infinite (%) | 0.0% |
| Infinite (n) | 0 |
</div>
<div class="col-sm-6">
<table class="stats ">
<tr>
<th>Mean</th>
<td>32.204</td>
</tr>
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>Maximum</th>
<td>512.33</td>
</tr>
<tr class="alert">
<th>Zeros (%)</th>
<td>1.7%</td>
</tr>
</table>
</div>
</div>

</ul>
<div class="tab-content">
<div role="tabpanel" class="tab-pane active row" id="quantiles-8081547523011189607">
<div class="col-md-4 col-md-offset-1">
<p class="h4">Quantile statistics</p>
<table class="stats indent">
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>5-th percentile</th>
<td>7.225</td>
</tr>
<tr>
<th>Q1</th>
<td>7.9104</td>
</tr>
<tr>
<th>Median</th>
<td>14.454</td>
</tr>
<tr>
<th>Q3</th>
<td>31</td>
</tr>
<tr>
<th>95-th percentile</th>
<td>112.08</td>
</tr>
<tr>
<th>Maximum</th>
<td>512.33</td>
</tr>
<tr>
<th>Range</th>
<td>512.33</td>
</tr>
<tr>
<th>Interquartile range</th>
<td>23.09</td>
</tr>
</table>
</div>
<div class="col-md-4 col-md-offset-2">
<p class="h4">Descriptive statistics</p>
<table class="stats indent">
<tr>
<th>Standard deviation</th>
<td>49.693</td>
</tr>
<tr>
<th>Coef of variation</th>
<td>1.5431</td>
</tr>
<tr>
<th>Kurtosis</th>
<td>33.398</td>
</tr>
<tr>
<th>Mean</th>
<td>32.204</td>
</tr>
<tr>
<th>MAD</th>
<td>28.164</td>
</tr>
<tr class="">
<th>Skewness</th>
<td>4.7873</td>
</tr>
<tr>
<th>Sum</th>
<td>28694</td>
</tr>
<tr>
<th>Variance</th>
<td>2469.4</td>
</tr>
<tr>
<th>Memory size</th>
<td>7.0 KiB</td>
</tr>
</table>
</div>
</div>
<div role="tabpanel" class="tab-pane col-md-8 col-md-offset-2" id="histogram-8081547523011189607">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAlgAAAGQCAYAAAByNR6YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD%2BnaQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAHgZJREFUeJzt3X1snYV58OE78YHl2MO1o%2BBEmpDSJXardpmSJeRjLKUyTVuKAlm%2BrC5Cb5EmpjrDS1U8qpKtDGTC1HabPDcShYGnLRJuokVTgLG8mlCXsXzRVQRVy%2BZQAdUi1c4X%2BfQSO37/2BtPXuiS0Ptwjo%2BvS%2BIPP4/tc58bn8PvPMckU0ZHR0cDAIA0U8s9AABAtRFYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQLJCuQeYLAYHz6R/z6lTp8T06XVx4sS5uHx5NP37T0Z2ms9O89lpadhrvkrY6a233lKW23UFawKbOnVKTJkyJaZOnVLuUaqGneaz03x2Whr2mm8y71RgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkK5R7AH4%2Bix59pdwjXLe/23RHuUcAgA%2BFK1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACSrysA6fvx4tLe3x6JFi2LJkiXR1dUVw8PDY%2BffeOONWLduXSxYsCBaW1tj%2B/btZZwWAKg2VRlYmzZtitra2tizZ0/s2LEj9u7dG729vRER8d5778WDDz4Yq1atioMHD0ZXV1ds2bIlDh06VN6hAYCqUXWB9c4778SBAweis7MzisVi3HbbbdHe3h7btm2LiIjdu3dHQ0NDbNiwIQqFQixbtixWrlw5dh4A4OdVdYHV398fDQ0NMXPmzLFjc%2BbMiaNHj8bp06ejv78/Wlpaxn3N3Llz4/Dhwx/2qABAlaq6v%2Bz53LlzUSwWxx278vH58%2Bff9/y0adPi/PnzaTMMDAzE4ODguGOFQm00NTWl3UZERE3NxOrjQqHy572y04m220pmp/nstDTsNd9k3mnVBVZtbW1cuHBh3LErH9fV1UWxWIwzZ86MOz80NBR1dXVpM/T19UVPT8%2B4Yxs3boyOjo6025iIGhvzdlxq9fXFa38SN8RO89lpadhrvsm406oLrObm5jh16lQcO3YsZsyYERERb731VsyaNStuueWWaGlpiddee23c1xw5ciSam5vTZmhra4vW1tZxxwqF2jh58lzabURMvFcE2fe/FGpqpkZ9fTFOn74QIyOXyz1OVbDTfHZaGvaarxJ2Wq4X91UXWLNnz46FCxfGk08%2BGY8//nicPHkytm7dGmvXro2IiBUrVsQ3v/nN6O3tjQ0bNsQPfvCD2LVrV2zdujVthqampqveDhwcPBPDw5P7ATuR7v/IyOUJNe9EYKf57LQ07DXfZNzpxLoEcp26u7tjeHg47rrrrli/fn0sX7482tvbIyKisbExnnvuuXjllVdiyZIlsXnz5ti8eXMsXbq0zFMDANWi6q5gRUTMmDEjuru7f%2Bb5efPmxQsvvPAhTgQATCZVeQULAKCcBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkq8rAOn78eLS3t8eiRYtiyZIl0dXVFcPDw2Pn33jjjVi3bl0sWLAgWltbY/v27WWcFgCoNlUZWJs2bYra2trYs2dP7NixI/bu3Ru9vb0REfHee%2B/Fgw8%2BGKtWrYqDBw9GV1dXbNmyJQ4dOlTeoQGAqlF1gfXOO%2B/EgQMHorOzM4rFYtx2223R3t4e27Zti4iI3bt3R0NDQ2zYsCEKhUIsW7YsVq5cOXYeAODnVSj3ANn6%2B/ujoaEhZs6cOXZszpw5cfTo0Th9%2BnT09/dHS0vLuK%2BZO3du7NixI22GgYGBGBwcHHesUKiNpqamtNuIiKipmVh9XChU/rxXdjrRdlvJ7DSfnZaGveabzDutusA6d%2B5cFIvFcceufHz%2B/Pn3PT9t2rQ4f/582gx9fX3R09Mz7tjGjRujo6Mj7TYmosbGunKPcN3q64vX/iRuiJ3ms9PSsNd8k3GnVRdYtbW1ceHChXHHrnxcV1cXxWIxzpw5M%2B780NBQ1NXl/ce/ra0tWltbxx0rFGrj5MlzabcRMfFeEWTf/1KoqZka9fXFOH36QoyMXC73OFXBTvPZaWnYa75K2Gm5XtxXXWA1NzfHqVOn4tixYzFjxoyIiHjrrbdi1qxZccstt0RLS0u89tpr477myJEj0dzcnDZDU1PTVW8HDg6eieHhyf2AnUj3f2Tk8oSadyKw03x2Whr2mm8y7nRiXQK5DrNnz46FCxfGk08%2BGWfPno2f/OQnsXXr1li7dm1ERKxYsSKOHTsWvb29cenSpdi3b1/s2rUr1qxZU%2BbJAYBqUXWBFRHR3d0dw8PDcdddd8X69etj%2BfLl0d7eHhERjY2N8dxzz8Urr7wSS5Ysic2bN8fmzZtj6dKlZZ4aAKgWVfcWYUTEjBkzoru7%2B2eenzdvXrzwwgsf4kQAwGRSlVewAADKSWABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMmqMrBefvnl%2BMQnPhELFiwY%2B6ezs3Ps/Pe///1YuXJlzJ8/P%2B6%2B%2B%2B549dVXyzgtAFBtCuUeoBTefPPNuO%2B%2B%2B2LLli1XnXv77bfjoYceij/5kz%2BJT3/607F79%2B7YtGlT7N69O2bOnFmGaQGAalOVV7DefPPN%2BJVf%2BZX3Pbdz585YtGhRfOYzn4lCoRBf%2BMIX4vbbb4%2B%2Bvr4PeUoAoFpV3RWsy5cvx49%2B9KMoFovx7LPPxsjISNx5553x8MMPx0c%2B8pE4cuRItLS0jPuauXPnxuHDh8s0MQBQbaousE6cOBGf%2BMQn4nOf%2B1x0d3fHyZMn45FHHonOzs747ne/G%2BfOnYtisTjua6ZNmxbnz59Pm2FgYCAGBwfHHSsUaqOpqSntNiIiamom1gXIQqHy572y04m220pmp/nstDTsNd9k3mnVBdaMGTNi27ZtYx8Xi8Xo7OyM9evXx9mzZ6NYLMbQ0NC4rxkaGoq6urq0Gfr6%2BqKnp2fcsY0bN0ZHR0fabUxEjY15Oy61%2BvritT%2BJG2Kn%2Bey0NOw132TcadUF1uHDh%2BPFF1%2BMr371qzFlypSIiLh48WJMnTo1br755mhpaYkf/ehH477myJEjP/N3tj6Itra2aG1tHXesUKiNkyfPpd1GxMR7RZB9/0uhpmZq1NcX4/TpCzEycrnc41QFO81np6Vhr/kqYaflenFfdYHV0NAQ27Zti4985CPxwAMPxMDAQHzzm9%2BM3/zN34ybb7457r333nj%2B%2Befj5Zdfjs9%2B9rOxe/fuOHDgQDz66KNpMzQ1NV31duDg4JkYHp7cD9iJdP9HRi5PqHknAjvNZ6elYa/5JuNOJ9YlkOswa9asePrpp%2BMf/uEfYvHixbFmzZqYN29e/OEf/mFERMyZMye%2B853vxNNPPx233357bN26Nf78z/88PvrRj5Z5cgCgWlTdFayIiMWLF8cLL7zwM88vX748li9f/iFOBABMJlV3BQsAoNwEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACSbeujQoXLPAABQVaZu27at3DMAAFSVqYcPHy73DAAAVaVw/vz5cs9QdQYGBmJwcHDcsUKhNpqamlJvp6ZmYv0KXaFQ%2BfNe2elE220ls9N8dloa9ppvMu%2B0UFdXV%2B4Zqk5fX1/09PSMO7Zx48bo6Ogo00SVobFx4vys1dcXyz1C1bHTfHZaGvaabzLutNDc3FzuGapOW1tbtLa2jjtWKNTGyZPnUm9nor0iyL7/pVBTMzXq64tx%2BvSFGBm5XO5xqoKd5rPT0rDXfJWw03K9uC%2BsWbOmLDdczZqamq56O3Bw8EwMD0/uB%2BxEuv8jI5cn1LwTgZ3ms9PSsNd8k3GnU5cuXVruGQAAqsrEeo8JAGACEFgAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkK5R7gGo0MDAQg4OD444VCrXR1NSUejs1NROrjwuFyp/3yk4n2m4rmZ3ms9PSsNd8k3mnAqsE%2Bvr6oqenZ9yxjRs3RkdHR5kmqgyNjXXlHuG61dcXyz1C1bHTfHZaGvaabzLuVGCVQFtbW7S2to47VijUxsmT51JvZ6K9Isi%2B/6VQUzM16uuLcfr0hRgZuVzucaqCneaz09Kw13yVsNNyvbgXWCXQ1NR01duBg4NnYnh4cj9gJ9L9Hxm5PKHmnQjsNJ%2Bdloa95puMO51Yl0AAACYAgQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkKxQ7gGq0cDAQAwODo47VijURlNTU%2Brt1NRMrD4uFCp/3is7nWi7rWR2ms9OS8Ne803mnQqsEujr64uenp5xxzZu3BgdHR1lmqgyNDbWlXuE61ZfXyz3CFXHTvPZaWnYa77JuFOBVQJtbW3R2to67lihUBsnT55LvZ2J9oog%2B/6XQk3N1KivL8bp0xdiZORyucepCnaaz05Lw17zVcJOy/XiXmCVQFNT01VvBw4Ononh4cn9gJ1I939k5PKEmncisNN8dloa9ppvMu50Yl0CAQCYAAQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQLL0wDpx4kSsWLEi9u/fP3bsjTfeiHXr1sWCBQuitbU1tm/fPu5rdu7cGStWrIj58%2BfH6tWr44c//GH2WAAAH5rUwPrBD34QbW1t8e67744de%2B%2B99%2BLBBx%2BMVatWxcGDB6Orqyu2bNkShw4dioiI/fv3xxNPPBFPPfVUHDx4MO6999748pe/HBcuXMgcDQDgQ1PI%2BkY7d%2B6M7u7u6OzsjK985Stjx3fv3h0NDQ2xYcOGiIhYtmxZrFy5MrZt2xa/%2Bqu/Gtu3b4977rknFi5cGBERX/rSl6Kvry9efvnlWLNmTdZ4VIC7/%2By1co9wQ/5u0x3lHgGACSotsH7jN34jVq5cGYVCYVxg9ff3R0tLy7jPnTt3buzYsSMiIo4cOXJVSM2dOzcOHz6cNdqHbmBgIAYHB8cdKxRqo6mpKfV2amr8Cl0pFQr2m%2BHKz6mf1zx2Whr2mm8y7zQtsG699db3PX7u3LkoFovjjk2bNi3Onz9/Xecnor6%2Bvujp6Rl3bOPGjdHR0VGmifggGhvryj1CVamvL177k7ghdloa9ppvMu40LbB%2BlmKxGGfOnBl3bGhoKOrq6sbODw0NXXW%2BsbGx1KOVTFtbW7S2to47VijUxsmT51JvZzK%2BIvgwZf/7mqxqaqZGfX0xTp%2B%2BECMjl8s9TlWw09Kw13yVsNNyvVgueWC1tLTEa6%2BN/92bI0eORHNzc0RENDc3R39//1XnP/WpT5V6tJJpamq66u3AwcEzMTzsATuR%2BPeVa2Tksp0ms9PSsNd8k3GnJb8EsmLFijh27Fj09vbGpUuXYt%2B%2BfbFr166x37tau3Zt7Nq1K/bt2xeXLl2K3t7eOH78eKxYsaLUowEAlETJr2A1NjbGc889F11dXdHd3R3Tp0%2BPzZs3x9KlSyPiv/6vwm984xvx2GOPxU9/%2BtOYO3duPPPMM9HQ0FDq0QAASqIkgfVv//Zv4z6eN29evPDCCz/z8%2B%2B777647777SjEKAMCHzm9JAwAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJBBYAQDKBBQCQTGABACQTWAAAyQQWAECyQrkHgEp195%2B9Vu4Rbsjfbbqj3CMA8P%2B5ggUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYAEAJBNYAADJ/DlYH8Dx48fjD/7gD%2BLAgQNRU1MT9957bzzyyCNRKFgnXA9/xhhQ7VzB%2BgA2bdoUtbW1sWfPntixY0fs3bs3ent7yz0WAFAhBNYNeuedd%2BLAgQPR2dkZxWIxbrvttmhvb49t27aVezQAoEJ4T%2BsG9ff3R0NDQ8ycOXPs2Jw5c%2BLo0aNx%2BvTpqK%2BvL%2BN0QCl4SxO4UQLrBp07dy6KxeK4Y1c%2BPn/%2BfNTX18fAwEAMDg6O%2B5xCoTaamppSZ6mpcQGS/zbRIoDSKRQ8N3wQV55Tq%2Bm5dcW39pR7hOv2fx9eXu4RUgmsG1RbWxsXLlwYd%2BzKx3V1dRER0dfXFz09PeM%2B53d/93fjoYceSp1lYGAg/s%2Bs/mhra0uPt8lqYGAg%2Bvr67DSRneaz09IYGBiIv/zLZ6tqr693fb6stz%2BZf1arJ9M/JM3NzXHq1Kk4duzY2LG33norZs2aFbfccktERLS1tcXf/M3fjPunra0tfZbBwcHo6em56moZH5yd5rPTfHZaGvaabzLv1BWsGzR79uxYuHBhPPnkk/H444/HyZMnY%2BvWrbF27dqxz2lqapp0pQ4A/DdXsD6A7u7uGB4ejrvuuivWr18fy5cvj/b29nKPBQBUCFewPoAZM2ZEd3d3uccAACpUzWOPPfZYuYfgg6urq4vFixeP/YI9Pz87zWen%2Bey0NOw132Td6ZTR0dHRcg8BAFBN/A4WAEAygQUAkExgAQAkE1gAAMkEFgBAMoEFAJBMYFFyx48fj/b29li0aFEsWbIkurq6Ynh4uNxjwYSwd%2B/eWLduXfzar/1a3HHHHfHEE0/E0NBQRES88cYbsW7duliwYEG0trbG9u3bx33tzp07Y8WKFTF//vxYvXp1/PCHPyzHXYBJSWBRcps2bYra2trYs2dP7NixI/bu3Ru9vb3lHgsq3okTJ%2BJ3fud34otf/GK8/vrrsXPnzjhw4EB897vfjffeey8efPDBWLVqVRw8eDC6urpiy5YtcejQoYiI2L9/fzzxxBPx1FNPxcGDB%2BPee%2B%2BNL3/5y3HhwoUy3yuYHAQWJfXOO%2B/EgQMHorOzM4rFYtx2223R3t4e27ZtK/doFasSrvg988wz8alPfSrmz58f999/f/z4xz%2B%2B4e9x%2BPDheOCBB2Lx4sVxxx13xO///u/HiRMnxs5f6%2BoLEdOnT49//ud/jtWrV8eUKVPi1KlT8Z//%2BZ8xffr02L17dzQ0NMSGDRuiUCjEsmXLYuXKlWOPre3bt8c999wTCxcujJtuuim%2B9KUvRWNjY7z88stlvleVY2RkJO6///742te%2BNnbs%2B9//fqxcuTLmz58fd999d7z66qtlnPDnk/E4rmSV8Fz5vxFYlFR/f380NDTEzJkzx47NmTMnjh49GqdPny7jZJWr3Ff8du7cGX/1V38Vf/EXfxH79%2B%2BPT37yk9HR0RE38pc%2BDA0NxW//9m/HggUL4p/%2B6Z/ixRdfjFOnTsXXv/71iIhrXn3hv/3iL/5iRETceeedsXLlyrj11ltj9erV0d/fHy0tLeM%2Bd%2B7cuXH48OGIiDhy5Mj/ep6Inp6eeP3118c%2Bfvvtt%2BOhhx6K3/u934vXX389Hnroodi0aVP89Kc/LeOUH0zG47jSlfu58loEFiV17ty5KBaL445d%2Bfj8%2BfPlGKmiVcIVv%2B9973vxW7/1W9Hc3By/8Au/EF/96lfj6NGjsX///uv%2BHkePHo2Pf/zjsXHjxrj55pujsbEx2tra4uDBgxER17z6wtV2794d//iP/xhTp06Njo6O931sTZs2bexxda3zk93evXtj9%2B7d8dnPfnbs2M6dO2PRokXxmc98JgqFQnzhC1%2BI22%2B/Pfr6%2Bso46QeT8TiuZJXwXHktAouSqq2tvep3Pq58PNn%2B4s/rUQlX/P7nlY%2BbbropZs%2BefUNXPn75l385nn322aipqRk79vd///fxyU9%2BMiLimldfuNq0adNi5syZ0dnZGXv27IlisTj2y%2B5XDA0NjT2urnV%2BMjt%2B/Hg8%2Buij8e1vf3tchFbTVb%2BMx3Elq4TnymsRWJRUc3NznDp1Ko4dOzZ27K233opZs2bFLbfcUsbJKlMlXPHLvvIxOjoaf/qnfxqvvvpqPProoyW5jWr1L//yL/H5z38%2BLl68OHbs4sWLcdNNN8XcuXOjv79/3OcfOXIkmpubI%2BK/Hnv/2/nJ6vLly9HZ2RkPPPBAfPzjHx93rpp%2BLqvpvryfSniuvBaBRUnNnj07Fi5cGE8%2B%2BWScPXs2fvKTn8TWrVtj7dq15R6tIlXCFb/MKx9nz56Njo6O2LVrV/z1X/91fOxjH0u/jWr2sY99LIaGhuLb3/52XLx4Mf7jP/4j/viP/zjWrl0bn/vc5%2BLYsWPR29sbly5din379sWuXbtizZo1ERGxdu3a2LVrV%2Bzbty8uXboUvb29cfz48VixYkWZ71V5Pf3003HzzTfH/ffff9W5avq5rKb78n4q4bnyWgQWJdfd3R3Dw8Nx1113xfr162P58uXR3t5e7rEqUiVc8fufVz4uXboUb7/99lVvnVzLu%2B%2B%2BG2vWrImzZ8/Gjh07xuIqIqKlpcXVletQV1cXzz77bPT398cdd9wR999/f/z6r/96fP3rX4/GxsZ47rnn4pVXXoklS5bE5s2bY/PmzbF06dKIiFi2bFl84xvfiMceeywWL14cL730UjzzzDPR0NBQ5ntVXn/7t38bBw4ciEWLFsWiRYvixRdfjBdffDEWLVpUVT%2BXWY/jSlUJz5XXNApUlC9%2B8YujX/nKV0bPnDkz%2Bu67747ec889o93d3R/a7X/ve98bXb58%2Bei//uu/jg4NDY1u2bJldMWKFaMXL1687u9x6tSp0U9/%2BtOjX/va10ZHRkauOn/ixInRRYsWjT7//POjFy9eHN27d%2B/oggULRvfu3Zt5V%2BCaHnnkkdFHHnlkdHR0dPTIkSOj8%2BbNG33ppZdGL126NPrSSy%2BNzps3b/THP/5xmae8cRmP40pX7ufKa5kyOlpF/88mVIFjx47F448/Hvv374%2BpU6fGqlWr4uGHHx73C%2BOlNDo6Gs8//3xs27YtTpw4EfPmzYs/%2BqM/io9%2B9KPX/T2ef/75eOqpp6JYLMaUKVPGnbvyp4m/%2Beab0dXVFf/%2B7/8e06dPj/b29li9enXqfYFrufJnYD311FMREbFnz5741re%2BFe%2B%2B%2B2780i/9UnR2dsadd95ZzhE/kIzHcaUr93PltQgsAIBkfgcLACCZwAIASCawAACSCSwAgGQCCwAgmcACAEgmsAAAkgksAIBkAgsAIJnAAgBIJrAAAJIJLACAZAILACCZwAIASCawAACS/T9aKENqDLKMpgAAAABJRU5ErkJggg%3D%3D"/>
</div>
<div role="tabpanel" class="tab-pane col-md-12" id="common-8081547523011189607">
| Value | Count | Frequency (%) | |
| 8.05 | 43 | 4.8% | |
| 13.0 | 42 | 4.7% | |
| 7.8958 | 38 | 4.3% | |
| 7.75 | 34 | 3.8% | |
| 26.0 | 31 | 3.5% | |
| 10.5 | 24 | 2.7% | |
| 7.925 | 18 | 2.0% | |
| 7.775 | 16 | 1.8% | |
| 26.55 | 15 | 1.7% | |
| 0.0 | 15 | 1.7% | |
| Other values (238) | 615 | 69.0% |
Minimum 5 values
| Value | Count | Frequency (%) | |
| 0.0 | 15 | 1.7% | |
| 4.0125 | 1 | 0.1% | |
| 5.0 | 1 | 0.1% | |
| 6.2375 | 1 | 0.1% | |
| 6.4375 | 1 | 0.1% |
Maximum 5 values
| Value | Count | Frequency (%) | |
| 227.525 | 4 | 0.4% | |
| 247.5208 | 2 | 0.2% | |
| 262.375 | 2 | 0.2% | |
| 263.0 | 4 | 0.4% | |
| 512.3292 | 3 | 0.3% |
parch
Numeric
| Distinct count | 7 |
|---|---|
| Unique (%) | 0.8% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Infinite (%) | 0.0% |
| Infinite (n) | 0 |
</div>
<div class="col-sm-6">
<table class="stats ">
<tr>
<th>Mean</th>
<td>0.38159</td>
</tr>
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>Maximum</th>
<td>6</td>
</tr>
<tr class="alert">
<th>Zeros (%)</th>
<td>76.1%</td>
</tr>
</table>
</div>
</div>

</ul>
<div class="tab-content">
<div role="tabpanel" class="tab-pane active row" id="quantiles-3970072562046918822">
<div class="col-md-4 col-md-offset-1">
<p class="h4">Quantile statistics</p>
<table class="stats indent">
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>5-th percentile</th>
<td>0</td>
</tr>
<tr>
<th>Q1</th>
<td>0</td>
</tr>
<tr>
<th>Median</th>
<td>0</td>
</tr>
<tr>
<th>Q3</th>
<td>0</td>
</tr>
<tr>
<th>95-th percentile</th>
<td>2</td>
</tr>
<tr>
<th>Maximum</th>
<td>6</td>
</tr>
<tr>
<th>Range</th>
<td>6</td>
</tr>
<tr>
<th>Interquartile range</th>
<td>0</td>
</tr>
</table>
</div>
<div class="col-md-4 col-md-offset-2">
<p class="h4">Descriptive statistics</p>
<table class="stats indent">
<tr>
<th>Standard deviation</th>
<td>0.80606</td>
</tr>
<tr>
<th>Coef of variation</th>
<td>2.1123</td>
</tr>
<tr>
<th>Kurtosis</th>
<td>9.7781</td>
</tr>
<tr>
<th>Mean</th>
<td>0.38159</td>
</tr>
<tr>
<th>MAD</th>
<td>0.58074</td>
</tr>
<tr class="">
<th>Skewness</th>
<td>2.7491</td>
</tr>
<tr>
<th>Sum</th>
<td>340</td>
</tr>
<tr>
<th>Variance</th>
<td>0.64973</td>
</tr>
<tr>
<th>Memory size</th>
<td>7.0 KiB</td>
</tr>
</table>
</div>
</div>
<div role="tabpanel" class="tab-pane col-md-8 col-md-offset-2" id="histogram-3970072562046918822">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAlgAAAGQCAYAAAByNR6YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD%2BnaQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAIABJREFUeJzt3Xt0VPW9/vEnyQSYJKQEIbWysCAQkUoPyDWCqCkRuQQQoSlyENHWVmIQftzEWEQwBQQ8iikWQUWBVaIsI5cGRCkHrVJuUkQESlBEpc0MkkASEnKb3x895HROcHYC35mdGd6vtbJc%2Bc7Ons9%2BzOiTPTs7YR6PxyMAAAAYE273AAAAAKGGggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADHPYPcDVwu0uMr7P8PAwNW8erTNnSlRd7TG%2B/1BARr6RjzUyskZGvpGPNX9m1LJlU6P7q6uQPIO1YcMGde3a1evj5ptv1s033yxJ2rFjh1JSUtSlSxcNHDhQ27dv9/r65cuXq1%2B/furSpYvGjh2rL774wo7DsBQeHqawsDCFh4fZPUqDRUa%2BkY81MrJGRr6Rj7VQzCgkC9bQoUO1f//%2Bmo8tW7aoWbNmyszM1IkTJ5Senq7HHntMe/fuVXp6uiZNmqT8/HxJUk5OjlatWqVXXnlFu3bt0k9%2B8hNNnDhRHg8/dQAAgLoJyYL17zwej6ZNm6Y77rhDw4YNU05Ojrp3767%2B/fvL4XBo0KBB6tGjh7KzsyVJb775pu677z516NBBjRs31pQpU3Tq1Cnt2rXL5iMBAADBIuSvwVq/fr3y8vK0dOlSSVJeXp4SEhK8tmnfvr2OHDlS8/ivfvWrmsciIyPVpk0bHTlyRL17967Tc7pcLrndbq81hyNK8fHxV3IotUREhHv9E7WRkW/kY42MrJGRb%2BRjLRQzCumCVV1drZdeekm/%2Bc1vFBMTI0kqKSmR0%2Bn02q5JkyY6f/58nR6vi%2BzsbGVlZXmtpaWlaeLEiZdzGJZiY53WG13lyMg38rFGRtbIyDfysRZKGYV0wdq1a5dcLpdGjhxZs%2BZ0OlVWVua1XVlZmaKjo%2Bv0eF2kpqYqKSnJa83hiFJBQUl9D8GniIhwxcY6de5cqaqqqo3uO1SQkW/kY42MrJGRb%2BRjzZ8ZxcXV/f/fJoV0wXr33XeVnJysqKiomrWEhAQdOnTIa7u8vLya3zDs0KGDjh07pjvvvFOSVFFRoRMnTtR6W9GX%2BPj4Wm8Hut1Fqqz0zwurqqrab/sOFWTkG/lYIyNrZOQb%2BVgLpYxC583OS9i3b5969OjhtTZ06FDt3r1bubm5qqysVG5urnbv3q1hw4ZJku69916tXr1aR44c0YULF7R48WK1aNFC3bt3t%2BMQAABAEArpM1jffPNNrTNJ7dq10%2B9//3stWrRIGRkZatWqlV588UW1bdtWkjRy5EgVFRUpLS1NZ86cUefOnbVs2TJFRkbacQgAACAIhXm4wVNA%2BONO7g5HuOLiolVQUBIyp1RNIyPfyMcaGVkjI9/Ix5o/M%2BJO7gAAACGCggUAAGAYBQsAAMAwChYAAIBhIf1bhFeD7hlb7B6hzjZP6mP3CAAABARnsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhDrsHgG/nzp3VCy8s1s6dH6m6ulpdu96iKVNmqkWLFnaPBgAAvgdnsBq4jIzpKi0tVXb2O3r77U0KDw/Xs88%2BY/dYAADAB85gNWBHjhzWoUOfaePGdxUdHSNJmjHjSZ0%2BfdrmyQAAgC8ULD9wuVxyu91eaw5HlOLj4%2Bu1n6NHP1fbtm21adN65eS8pdLSMvXunaiJE/%2BfHI5wRUQE1wlIhyPw817MKNiyChTysUZG1sjIN/KxFooZUbD8IDs7W1lZWV5raWlpmjhxYr32U1FRquPH8%2BRyndL69etVVlam6dOna968p7Vs2TKTIwdEXFy0bc8dG%2Bu07bmDAflYIyNrZOQb%2BVgLpYwoWH6QmpqqpKQkrzWHI0oFBSX12k9VleTxSBMmTFJFRZgiIpx66KHf6KGH7te337rVtGmMybH9rr7Hb0JERLhiY506d65UVVXVAX/%2Bho58rJGRNTLyjXys%2BTMju364p2D5QXx8fK23A93uIlVW1u%2Bb5vrr28jjqVZZ2QVFRERKksrLKyVJlZVVQfdCre/xm1RVVW3r8zd05GONjKyRkW/kYy2UMgqdNztDUI8evXXdda00b94cnT9fosLCQi1fvlS33XaHoqLse7sNAAD4RsFqwBwOh7KyXlZERIRGjx6hX/ziHrVsGa%2BZM2fZPRoAAPCBtwgbuBYtWurpp%2BfZPQYAAKgHzmABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYFhIFqzc3Fx16tRJXbt2rfmYNm2a3WNdlp07/6L7709V//59NWbMSH300Yd2jwQAACw47B7AHw4ePKhhw4Zp3rx5do9yRb7%2B%2BqQyMmZo9uxM3XprX%2B3YsV2zZj2utWtz1LJlvN3jAQCA7xGSZ7AOHjyom2%2B%2B2e4xrtjmzZv0H//RRf363SGHw6Gf/SxZXbp004YNOXaPBgAAfAi5M1jV1dU6dOiQnE6nVqxYoaqqKt1%2B%2B%2B2aOnWqfvCDHwRkBpfLJbfb7bXmcEQpPr5%2BZ52%2B%2BupLtW/fQQ7H//bgG264QcePH5PDEa6IiODqx/9%2BHIFyMaNgyypQyMcaGVkjI9/Ix1ooZhRyBevMmTPq1KmTBgwYoCVLlqigoEAzZszQtGnT9PLLLwdkhuzsbGVlZXmtpaWlaeLEifXaT3l5meLiYhUXF12z1qxZU504ccFrLVjYOXNsrNO25w4G5GONjKyRkW/kYy2UMgq5gtWiRQutWbOm5nOn06lp06bp5z//uYqLixUTE%2BP3GVJTU5WUlOS15nBEqaCgpF77cTgaqbCwyOvrCguL1KhRExUUlARd06/v8ZsQERGu2Finzp0rVVVVdcCfv6EjH2tkZI2MfCMfa/7MyK4f7kOuYB05ckSbNm3SlClTFBYWJkkqLy9XeHi4GjVqFJAZ4uPja70d6HYXqbKyft80bdrcoL///ajX133xxRfq2PGmeu%2BrIbBz5qqq6qDMLFDIxxoZWSMj38jHWihlFFynQOqgWbNmWrNmjVasWKHKykqdOnVKCxcu1D333BOwgmXK3XcP1v79%2B7Rt23uqrKzUtm3vaf/%2BfRowYJDdowEAAB9CrmBde%2B21WrZsmbZt26aePXvq3nvvVefOnTVr1iy7R6u3H/%2B4jebNW6RVq17TwIFJWrlyuTIzF%2Bj6639s92gAAMCHkHuLUJJ69uyptWvX2j2GEb16JapXr0S7xwAAAPUQcmewAAAA7EbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGGZZsKqqqgIxBwAAQMiwLFj9%2BvXTs88%2Bq7y8vEDMAwAAEPQsC9ajjz6qTz75REOGDNGoUaO0du1aFRUVBWI2AACAoGRZsEaPHq21a9dqy5YtuvXWW7V8%2BXL17dtXU6ZM0ccffxyIGQEAAIJKnS9yb9OmjSZPnqwtW7YoLS1N27Zt00MPPaSkpCS99tprXKsFAADwPxx13fDAgQN65513lJubq/LyciUnJ2vEiBHKz8/XCy%2B8oIMHD%2Bq5557z56wAAABBwbJgLV26VOvXr9dXX32lzp07a/LkyRoyZIhiYmJqtomIiNCsWbP8OigAAECwsCxYq1ev1tChQzVy5Ei1b9/%2Bktu0a9dOU6dONT4cAABAMLIsWB988IGKi4tVWFhYs5abm6vExETFxcVJkjp16qROnTr5b0oAAIAgYnmR%2B%2Beff64BAwYoOzu7Zm3hwoVKSUnR3//%2Bd78OBwAAEIwsC9azzz6ru%2B66S5MnT65Ze//999WvXz/Nnz/fr8M1dFVVVRo7dqwef/zxmrUdO3YoJSVFXbp00cCBA7V9%2B3avr1mz5nXdc88g9e/fV48%2B%2BrBOnjwR4KkBAIC/WRasQ4cO6eGHH1ajRo1q1iIiIvTwww/rb3/7m1%2BHa%2BiysrK0d%2B/ems9PnDih9PR0PfbYY9q7d6/S09M1adIk5efnS5I2b96kdeuytXjxi/rTn7bpxhtvUkbGdHk8HrsOAQAA%2BIFlwYqJidHJkydrrf/zn/9UkyZN/DJUMNi5c6e2bt2qu%2B66q2YtJydH3bt3V//%2B/eVwODRo0CD16NGj5u3VDRtydM89I3XDDe3UuHFjPfJIuvLz87V//z67DgMAAPiB5UXuAwYM0OzZs/X000/rpz/9qcLCwnTw4EHNmTNHycnJgZixwfnuu%2B%2BUkZGhpUuXauXKlTXreXl5SkhIkMvlktvtliQ1a9ZMe/bs0YABKTpx4gvdf/8Dcjj%2B1WsdjkZq3bq1vvjimHr27FnvOSIi6nyf2Abh4nEH0sWMgi2rQCEfa2RkjYx8Ix9roZiRZcGaMmWKvv76az344IMKCwurWU9OTtb06dP9OlxDVF1drWnTpmn8%2BPHq2LGj12MlJSVyOp3Kzs5WVlaW12PvvrtR58%2BfV8uWcYqLi65Zj4mJlsdT6bUWquw8xthYp23PHQzIxxoZWSMj38jHWihlZFmwnE6nli1bpi%2B//FJHjx5VZGSk2rVrpzZt2gRgvIZn2bJlatSokcaOHVvrMafTqbKyMo0fP15JSUmSpNdee035%2BfkaMCBFK1e%2BrtOnC1VQUFLzNcXFJQoPj/Raq6tga/qXc4xXKiIiXLGxTp07V6qqquqAP39DRz7WyMgaGflGPtb8mZFdP9zX%2BU/ltG3bVm3btvXnLEFh/fr1crlc6t69uySprKxM0r9%2Bs3LMmDE6dOiQ4uPjFR8fL0kqLCxUt27d1Lx5C91www3Ky8tT7959JUmVlZX6%2Buuv9eMf36DKytB/0dl5jFVV1VdFxpeLfKyRkTUy8o18rIVSRpYF68svv9ScOXO0b98%2BVVRU1Hr88OHDfhmsodqyZYvX5xdv0TB//nwdP35cr732mnJzc3XXXXdp69at2r17tzIyMiRJgwcP1SuvvKxevW7V9df/WC%2B/vFTNmzdXly63BPw4AACA/1gWrNmzZ%2BvUqVOaOnWqmjZtGoiZgla7du30%2B9//XosWLVJGRoZatWqlF198UW3btpXbXaTBg4epqKhYTzwxTYWFBbrppk569tnn5XDU%2BUQiAAAIAmEei5sw/fSnP9Xrr7%2Burl27BmqmkOR2Fxnfp8MRruRFHxrfr79sntQn4M/pcIQrLi5aBQUlIXPa2STysUZG1sjIN/Kx5s%2BMWra05%2BSQ5VXScXFxio4O/d9wAwAAMMWyYI0dO1bPPfeciorMn4EBAAAIRZYX/%2BzYsUN/%2B9vf1KtXL11zzTVefzJHkrZt2%2Ba34QAAAIKRZcHq1auXevXqFYhZAAAAQoJlwXr00UcDMQcAAEDIqNOtwI8cOaKZM2fqF7/4hfLz87VmzRrt2rXL37MBAAAEJcuC9dlnn2nUqFH65ptv9Nlnn6m8vFyHDx/Wgw8%2BqO3btwdiRgAAgKBiWbAWLVqkBx98UKtWrVJkZKQk6ZlnntH9999f6w8aAwAAoI5nsIYPH15rffTo0friiy/8MhQAAEAwsyxYkZGRKi4urrV%2B6tQpOZ1OvwwFAAAQzCwLVv/%2B/bV48WIVFBTUrB0/flyZmZm64447/DkbAABAULIsWDNmzFBZWZluvfVWlZaWasSIERoyZIgcDoemT58eiBkBAACCiuV9sGJiYrR27Vrt3LlTn3/%2Buaqrq5WQkKDbbrtN4eF1ussDAADAVcWyYF2UmJioxMREf84CAAAQEiwLVlJSksLCwr73cf4WIQAAgDfLgnXPPfd4FayKigp99dVX%2BuCDDzRp0iS/DgcAABCMLAtWenr6JddXr16tffv26f777zc%2BFAAAQDC77KvU77zzTu3YscPkLAAAACHhsgvW7t271bhxY5OzAAAAhATLtwj/71uAHo9HxcXFOnr0KG8PAgAAXIJlwbruuutq/RZhZGSkxo0bp5SUFL8NBgAAEKwsC9b8%2BfMDMQcAAEDIsCxYe/bsqfPOevTocUXDAAAAhALLgvXAAw/I4/HUfFx08W3Di2thYWE6fPiwn8YEAAAIHpYF68UXX9S8efM0Y8YM9e7dW5GRkTpw4IBmz56t%2B%2B67T3feeWcg5gQAAAgalrdpWLBggZ566in1799fMTExaty4sXr27Kk5c%2Bbo1VdfVatWrWo%2BAAAAUIeC5XK59KMf/ajWekxMjAoKCvwyFAAAQDCzLFhdunTRc889p%2BLi4pq1wsJCLVy4UImJiX4dDgAAIBhZXoP15JNPaty4cerXr5/atGkjSfryyy/VsmVLvfHGG/6eDwAAIOhYFqx27dopNzdXGzdu1PHjxyVJ9913nwYPHiyn0%2Bn3AQEAAIKNZcGSpNjYWI0aNUrffPONWrduLelfd3MHAABAbZbXYHk8Hi1atEg9evTQkCFD9M9//lMzZszQzJkzVVFREYgZAQAAgoplwVq1apXWr1%2Bvp556So0aNZIk9e/fX3/%2B85/1wgsv%2BH1AAACAYGNZsLKzszVr1iyNGDGi5u7tgwYNUmZmpv70pz/5fUAAAIBgY1mwvvnmG91000211m%2B88UadPn3aL0MBAAAEM8uC1apVK3366ae11nfs2FFzwTsCx%2B12KT391xo06GdKSupr9zgAAOASLH%2BL8KGHHtLTTz%2Bt/Px8eTwe7dy5U2vXrtWqVas0c%2BbMQMyIfzNnzm8VFhamtWvflsdTrV%2B89rndIwEAgP/DsmDde%2B%2B9qqys1EsvvaSysjLNmjVL11xzjSZPnqzRo0cHYkb8j7KyMu3fv08vvfSKYmN/oPPni62/CAAABJxlwdqwYYPuvvtupaam6syZM/J4PLrmmmsCMVvQcrlccrvdXmsOR5Ti4%2BOvaL//%2BMc3kqSEhAQtX75Ub7zxmmLuff6K9hlIDoflO9LGRUSEe/0T3sjHGhlZIyPfyMdaKGYU5vF4PL426Nmzp/74xz%2BqXbt2gZop6L344ovKysryWktLS9PEiROvaL979%2B7VmDFjdPjwYZWXlys8PFy3Pv3nK9pnIO3NvNvuEQAACAjLM1ht2rTR0aNHKVj1kJqaqqSkJK81hyNKBQUlV7Tfysp/3SbjH//4TlFRUYqI8NmNG5wrPf7LERERrthYp86dK1VVVXXAn7%2BhIx9rZGSNjHwjH2v%2BzCguLtro/urKsmB16NBBU6dO1YoVK9SmTRs1btzY6/F58%2Bb5bbhgFR8fX%2BvtQLe7SJWVV/ZN06rV9QoLC9Obb67Vf/7nA1e0Lztc6fFfiaqqalufv6EjH2tkZI2MfCMfa6GUkWXBOnnypLp16yZJta4rQmA1adJEffverj/8IUv9%2Bw%2BQ09nE7pEAAMAlXLJgzZs3T4899piioqK0atWqQM8EHzIyZmvJksUaP36MwsIk3TXX7pEAAMD/ccnL9d944w2VlpZ6rT300ENyuVwBGQrfLyYmRk888ZQ2b/6ztm79b7vHAQAAl3DJgnWpXyz85JNPdOHCBb8PBAAAEOxC54YTAAAADQQFCwAAwLDvLVhhYWGBnAMAACBkfO9tGp555hmve15VVFRo4cKFio72vmEX98ECAADwdsmC1aNHj1r3vOratasKCgpUUFAQkMEAAACC1SULFve%2BAgAAuHxc5A4AAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDAlKwjhw5ovHjx6tnz57q06ePpk%2BfrjNnzkiSDhw4oFGjRqlr165KSkrSW2%2B95fW1OTk5Sk5OVpcuXTRixAjt378/ECMDAABcNr8XrLKyMv3yl79U165d9Ze//EWbNm1SYWGhnnjiCZ09e1YPP/ywhg8frj179igzM1Pz5s3Tp59%2BKknatWuX5s6dq/nz52vPnj0aOnSoHnnkEZWWlvp7bAAAgMvm94J16tQpdezYUWlpaWrUqJHi4uKUmpqqPXv2aOvWrWrWrJnGjBkjh8OhxMREpaSkaM2aNZKkt956S4MHD1a3bt0UGRmpBx54QHFxccrNzfX32AAAAJfN4e8nuOGGG7RixQqvtXfffVc/%2BclPdOzYMSUkJHg91r59e61bt06SlJeXp3vvvbfW40eOHPHv0FfI5XLJ7XZ7rTkcUYqPjzf6PBERwXUJncMR%2BHkvZhRsWQUK%2BVgjI2tk5Bv5WAvFjPxesP6dx%2BPR888/r%2B3bt2v16tV644035HQ6vbZp0qSJzp8/L0kqKSnx%2BXhDlZ2draysLK%2B1tLQ0TZw40aaJGoa4uGjbnjs21mm90VWMfKyRkTUy8o18rIVSRgErWMXFxZo5c6YOHTqk1atX68Ybb5TT6VRRUZHXdmVlZYqO/tf/iJ1Op8rKymo9HhcXF6ixL0tqaqqSkpK81hyOKBUUlBh9nmBr%2BqaPvy4iIsIVG%2BvUuXOlqqqqDvjzN3TkY42MrJGRb%2BRjzZ8Z2fXDfUAK1smTJ/WrX/1K1113ndatW6fmzZtLkhISEvTRRx95bZuXl6cOHTpIkjp06KBjx47Verxfv36BGPuyxcfH13o70O0uUmXl1f3CsvP4q6qqr/r8fSEfa2RkjYx8Ix9roZSR30%2BBnD17VuPGjdMtt9yiV155paZcSVJycrJOnz6tlStXqqKiQn/961%2B1cePGmuuuRo4cqY0bN%2Bqvf/2rKioqtHLlSn333XdKTk7299gAAACXze9nsN5%2B%2B22dOnVKmzdv1pYtW7we279/v1599VVlZmZqyZIlat68uZ588kn17t1bkpSYmKinnnpKs2fPVn5%2Bvtq3b6/ly5erWbNm/h4bAADgsoV5PB6P3UNcDdzuIuuN6snhCFfyog%2BN79dfNk/qE/DndDjCFRcXrYKCkpA57WwS%2BVgjI2tk5Bv5WPNnRi1bNjW6v7oKrqukAQAAggAFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABjmsHsAXD0GPv%2BR3SPUy%2BZJfeweAQAQpDiDBQAAYBgFCwAAwDAKlg9nzpxRcnKydu3aVbN24MABjRo1Sl27dlVSUpLeeustr6/JyclRcnKyunTpohEjRmj//v2BHhsAANiMgvU99u3bp9TUVJ08ebJm7ezZs3r44Yc1fPhw7dmzR5mZmZo3b54%2B/fRTSdKuXbs0d%2B5czZ8/X3v27NHQoUP1yCOPqLS01K7DAAAANqBgXUJOTo6mTp2qyZMne61v3bpVzZo105gxY%2BRwOJSYmKiUlBStWbNGkvTWW29p8ODB6tatmyIjI/XAAw8oLi5Oubm5dhwGAACwCQXrEvr27av33ntPgwYN8lo/duyYEhISvNbat2%2BvI0eOSJLy8vJ8Pg4AAK4O3KbhElq2bHnJ9ZKSEjmdTq%2B1Jk2a6Pz5816Pu1wuud1uSdKFCxf07bff6syZ04qPjzc6Z0QE/difHI7Qz/fi9xDfS9%2BPjKyRkW/kYy0UM6Jg1YPT6VRRUZHXWllZmaKjo2seLysrU3Z2trKysry269ixoyZOnBiwWXHl4uKi7R4hYGJjndYbXeXIyBoZ%2BUY%2B1kIpIwpWPSQkJOijj7xvlpmXl6cOHTpIkjp06KBjx44pLS1NSUlJkqT09HQNGzZMAwakqKCgxOg8odT0GyLT/74aooiIcMXGOnXuXKmqqqrtHqdBIiNrZOQb%2BVjzZ0Z2/bBMwaqH5ORkLVy4UCtXrtSYMWO0b98%2Bbdy4UUuXLpUkjRw5UmlpaRo4cKC6deumNWvWqLi4WOPGjVNFRYQqK3lhBZOr6d9XVVX1VXW8l4OMrJGRb%2BRjLZQyomDVQ1xcnF599VVlZmZqyZIlat68uZ588kn17t1bkpSYmKinnnpKs2fPVn5%2Bvtq3b6/ly5erWbNmcrsW6ZO6AAAHS0lEQVSLLPYOAABCBQXLwtGjR70%2B79y5s9auXfu92w8bNkzDhg3z91gAAKAB4yIeAAAAwyhYAAAAhlGwAAAADKNgAQAAGMZF7kCIGPj8R9YbNRCbJ/WxewQA8CvOYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDGkTB%2Bu677zRhwgR1795dvXr1UmZmpiorK%2B0eCwAA4LI0iII1adIkRUVF6cMPP9S6deu0c%2BdOrVy50u6xAAAALovtBeurr77S7t27NW3aNDmdTrVu3VoTJkzQmjVr7B4NAADgsjjsHuDYsWNq1qyZfvjDH9astWvXTqdOndK5c%2BcUGxtr43QAIHXP2GL3CCFr86Q%2Bdo9QLwOf/8juEeol2PINJbYXrJKSEjmdTq%2B1i5%2BfP38%2BKAuWy%2BWS2%2B32WnM4ohQfH2/0eSIibD8BGdIcDvL1l2DKlteZfwXT90IwCpZ8L77OQun1ZnvBioqKUmlpqdfaxc%2Bjo6PtGOmKZWdnKysry2vt0UcfVXp6utHncblcGnftMaWmphovb6HC5XIpOzv7qshob%2Bbd9f6aqymfy8XrzNrV9H3E68w/XC6XXn99RUhlZHtV7NChgwoLC3X69OmatePHj%2Bvaa69V06ZNbZzs8qWmpurtt9/2%2BkhNTTX%2BPG63W1lZWbXOluF/kZFv5GONjKyRkW/kYy0UM7L9DFabNm3UrVs3/e53v9OcOXNUUFCgpUuXauTIkXaPdtni4%2BNDpoEDAID6s/0MliQtWbJElZWV%2BtnPfqaf//znuu222zRhwgS7xwIAALgstp/BkqQWLVpoyZIldo8BAABgRMTs2bNn2z0ELl90dLR69uwZtL8QEAhk5Bv5WCMja2TkG/lYC7WMwjwej8fuIQAAAEJJg7gGCwAAIJRQsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgICjt37tSoUaN0yy23qE%2BfPpo7d67KysrsHssWVVVVuu%2B%2B%2B/T444/bPQoA1Mkvf/lLde7cWV27dq35%2BOCDDy65bWFhoaZPn65evXqpR48emjBhglwuV4AnvnIULDR4Z86c0a9//WuNHj1ae/fuVU5Ojnbv3q2XX37Z7tFssWTJEu3fv9/uMQCgzj777DO98sor2r9/f81Hv379Lrltenq6zp8/r/fee0/bt29XRESEfvvb3wZ44ivXIP7YM%2BBL8%2BbN9fHHHysmJkYej0eFhYW6cOGCmjdvbvdoAffxxx/r/fff11133WX3KABQJ19//bXOnj2rTp06WW772Wef6cCBAzX/zZekuXPnyu12%2B3tM4ziDhaBw8YV2%2B%2B23KyUlRS1bttSIESNsniqwTp8%2BrSeffFKLFy%2BW0%2Bm0exwAqJODBw8qOjpakydPVu/evTVkyBCtW7fuktt%2B%2Bumnat%2B%2Bvd58800lJyerb9%2B%2BWrBggVq2bBngqa8cBQtBZevWrfrggw8UHh6uiRMn2j1OwFRXV2vatGkaP368OnbsaPc4AFBn5eXl6tKliyZPnqwPP/xQjz/%2BuDIzM7V58%2BZa2549e1ZHjx7ViRMnlJOTo3feeUf5%2BfmaMWOGDZNfGQoWgkqTJk30wx/%2BUNOmTdOHH36os2fP2j1SQPzhD39Q48aNNXbsWLtHAYB6GT58uFasWKFOnTopMjJSffv21fDhwy9ZsBo1aiRJysjIUExMjFq0aKFJkyZpx44dKikpCfToV4RrsNDgffLJJ3riiSe0YcOGmhdfeXm5IiMjr5q3yjZs2CCXy6Xu3btLUs1vUL7//vvau3evnaMBgE/r1q1TdHS0Bg4cWLNWXl6uxo0b19q2ffv2qq6uVkVFRc3j1dXVkiSPxxOYgQ3hDBYavBtvvFFlZWVavHixysvL9e2332rBggUaOXJkTeEKdVu2bNEnn3yivXv3au/evRoyZIiGDBlCuQLQ4BUXF2vu3Lk6fPiwqqurtX37dm3atEmpqam1tr311lvVunVrPfHEEyopKdGZM2f0X//1X%2Brfv3/NtbjBgjNYaPCio6O1YsUK/e53v1OfPn3UtGlTpaSkKC0tze7RAAAWxo0bp/PnzystLU3fffedWrdurQULFtSckf93kZGRWrVqlebPn68BAwbowoULSkpKUkZGhg2TX5kwT7CdcwMAAGjgeIsQAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADDs/wOqES5SRtHfDAAAAABJRU5ErkJggg%3D%3D"/>
</div>
<div role="tabpanel" class="tab-pane col-md-12" id="common-3970072562046918822">
| Value | Count | Frequency (%) | |
| 0 | 678 | 76.1% | |
| 1 | 118 | 13.2% | |
| 2 | 80 | 9.0% | |
| 5 | 5 | 0.6% | |
| 3 | 5 | 0.6% | |
| 4 | 4 | 0.4% | |
| 6 | 1 | 0.1% |
Minimum 5 values
| Value | Count | Frequency (%) | |
| 0 | 678 | 76.1% | |
| 1 | 118 | 13.2% | |
| 2 | 80 | 9.0% | |
| 3 | 5 | 0.6% | |
| 4 | 4 | 0.4% |
Maximum 5 values
| Value | Count | Frequency (%) | |
| 2 | 80 | 9.0% | |
| 3 | 5 | 0.6% | |
| 4 | 4 | 0.4% | |
| 5 | 5 | 0.6% | |
| 6 | 1 | 0.1% |
pclass
Numeric
| Distinct count | 3 |
|---|---|
| Unique (%) | 0.3% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Infinite (%) | 0.0% |
| Infinite (n) | 0 |
</div>
<div class="col-sm-6">
<table class="stats ">
<tr>
<th>Mean</th>
<td>2.3086</td>
</tr>
<tr>
<th>Minimum</th>
<td>1</td>
</tr>
<tr>
<th>Maximum</th>
<td>3</td>
</tr>
<tr class="ignore">
<th>Zeros (%)</th>
<td>0.0%</td>
</tr>
</table>
</div>
</div>

</ul>
<div class="tab-content">
<div role="tabpanel" class="tab-pane active row" id="quantiles8885073346795181634">
<div class="col-md-4 col-md-offset-1">
<p class="h4">Quantile statistics</p>
<table class="stats indent">
<tr>
<th>Minimum</th>
<td>1</td>
</tr>
<tr>
<th>5-th percentile</th>
<td>1</td>
</tr>
<tr>
<th>Q1</th>
<td>2</td>
</tr>
<tr>
<th>Median</th>
<td>3</td>
</tr>
<tr>
<th>Q3</th>
<td>3</td>
</tr>
<tr>
<th>95-th percentile</th>
<td>3</td>
</tr>
<tr>
<th>Maximum</th>
<td>3</td>
</tr>
<tr>
<th>Range</th>
<td>2</td>
</tr>
<tr>
<th>Interquartile range</th>
<td>1</td>
</tr>
</table>
</div>
<div class="col-md-4 col-md-offset-2">
<p class="h4">Descriptive statistics</p>
<table class="stats indent">
<tr>
<th>Standard deviation</th>
<td>0.83607</td>
</tr>
<tr>
<th>Coef of variation</th>
<td>0.36215</td>
</tr>
<tr>
<th>Kurtosis</th>
<td>-1.28</td>
</tr>
<tr>
<th>Mean</th>
<td>2.3086</td>
</tr>
<tr>
<th>MAD</th>
<td>0.76197</td>
</tr>
<tr class="">
<th>Skewness</th>
<td>-0.63055</td>
</tr>
<tr>
<th>Sum</th>
<td>2057</td>
</tr>
<tr>
<th>Variance</th>
<td>0.69902</td>
</tr>
<tr>
<th>Memory size</th>
<td>7.0 KiB</td>
</tr>
</table>
</div>
</div>
<div role="tabpanel" class="tab-pane col-md-8 col-md-offset-2" id="histogram8885073346795181634">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAlgAAAGQCAYAAAByNR6YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD%2BnaQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAH7FJREFUeJzt3X1wVfWd%2BPEPEJAQioQp6ey6f9gV0KnGDQ8qFMEhI90iD7IUNrNlqMWFdt1IWketKHV1llJlWta2oLsuip3dOluEyrRuRbGVrbvVpYCudZilJbUOKqOkojwEQiQ5vz865te7KAT8Xm5y8nrNMEzOObn3%2B%2BHck7xzbxJ6ZVmWBQAAyfQu9QIAAPJGYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAILGyUi%2Bgp2hqOpj8Nnv37hVDhlTEvn3N0d6eJb/9UsnrXBH5nS2vc0WYrTvK61wR%2BZ2tmHMNHfqRpLfXWZ7B6sZ69%2B4VvXr1it69e5V6KUnlda6I/M6W17kizNYd5XWuiPzOlse5BBYAQGICCwAgMYEFAJCYwAIASExgAQAkJrAAABITWAAAiflFo0Wwd%2B/eaGpqKthWVjYgqqqqkt5Pnz69C/7Oi7zOFZHf2fI6V4TZuqO8zhWR39nyOFevLMvy86tgu4iVK1fGqlWrCrbV19dHQ0NDiVYEAJxJAqsIzuQzWIMGlceBA0eira096W2XUl7nisjvbHmdK8Js3VFe54rI72zFnKuysiLp7XWWlwiLoKqq6riYamo6GMeOFediaGtrL9ptl1Je54rI72x5nSvCbN1RXueKyO9seZorPy92AgB0EQILACAxLxECQE5N%2BdbPS72ETtu27NOlXkJSnsECAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAAS69GB1dbWFvPmzYvFixd3bPvZz34W06dPj5qampgyZUps3ry54H1Wr14dEydOjJqampg3b168/PLLZ3rZAEAX16MDa9WqVbFt27aOt1955ZVYtGhRfOlLX4pt27bFokWL4stf/nK8%2BeabERGxYcOG%2BNd//dd48MEHY8uWLXHhhRdGQ0NDZFlWqhEAgC6oxwbWc889F5s2bYpPfepTHds2bNgQY8aMiSuvvDLKysriqquuiksuuSTWrl0bERGPPPJIfPazn43hw4fHWWedFTfeeGPs2bMntmzZUqoxAIAuqEcG1ltvvRVLliyJFStWRHl5ecf2xsbGGDFiRMGxw4YNi507d77v/r59%2B8a5557bsR8AICKirNQLONPa29vj5ptvjvnz58cFF1xQsK%2B5ubkguCIi%2BvfvH4cPH%2B7U/vfs3bs3mpqaCraVlQ2IqqqqVGNERESfPr0L/s6LvM4Vkd/Z8jpXhNm6o7zOFZHv2SLyNVePC6z7778/%2BvXrF/PmzTtuX3l5ebS0tBRsa2lpiYqKik7tf8/atWtj1apVBdvq6%2BujoaEhxQjHGTSo/OQHdUN5nSsiv7Plda4Is3VHeZ0rIr%2Bz5WmuHhdYP/zhD2Pv3r0xZsyYiIiOYPrJT34Sc%2BfOjR07dhQc39jYGBdddFFERAwfPjx27doVkyZNioiId999N1555ZXjXlasq6uL2tragm1lZQPi7bebk87Sp0/vGDSoPA4cOBJtbe1Jb7uU8jpXRH5ny%2BtcEWbrjvI6V0S%2BZ4uIosxVWVlx8oOKoMcF1hNPPFHw9nu/ouHuu%2B%2BO3/zmN/HQQw/F448/Hp/61Kdi06ZN8Ytf/CKWLFkSERGf%2BcxnYuXKlTFx4sT4%2BMc/Hvfcc0989KMf7Yi191RVVR33cmBT08E4dqw4F0NbW3vRbruU8jpXRH5ny%2BtcEWbrjvI6V0R%2BZ8vTXD0usE7kvPPOi3vvvTe%2B%2Bc1vxpIlS%2BKcc86JlStXxsc//vGIiJg9e3YcPHgw6uvrY9%2B%2BfVFdXR33339/9O3bt8QrBwC6kh4fWHfffXfB2xMmTIgJEya877G9evWKa6%2B9Nq699tozsTQAoJvKz7frAwB0EQILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBILLeB9dxzz8WcOXNi1KhRMX78%2BFi6dGm0tLRERMSLL74Yc%2BbMiZEjR0ZtbW2sW7eu4H03bNgQkydPjpqampg1a1a88MILpRgBAOimchlY%2B/btiy9%2B8YvxV3/1V7Ft27bYsGFD/OIXv4h//ud/jv3798cXvvCFmDlzZmzdujWWLVsWd911V/zyl7%2BMiIgtW7bE0qVL4%2B67746tW7fGjBkz4rrrrosjR46UeCoAoLvIZWANGTIknn322Zg1a1b06tUr3nnnnTh69GgMGTIkNm3aFIMHD465c%2BdGWVlZjBs3LqZPnx4PP/xwRESsW7cupk6dGqNHj46%2BffvG5z//%2BaisrIzHH3%2B8xFMBAN1FLgMrImLgwIEREXHFFVfE9OnTY%2BjQoTFr1qzYtWtXjBgxouDYYcOGxc6dOyMiorGx8YT7AQBOpqzUCyi2TZs2xf79%2B%2BOmm26KhoaG%2BNjHPhbl5eUFx/Tv3z8OHz4cERHNzc0n3N8Ze/fujaampoJtZWUDoqqq6jSneH99%2BvQu%2BDsv8jpXRH5ny%2BtcEWbrjvI6V0S%2BZ4vI11y5D6z%2B/ftH//794%2Babb445c%2BbEvHnz4uDBgwXHtLS0REVFRURElJeXd3wz/B/ur6ys7PR9rl27NlatWlWwrb6%2BPhoaGk5zihMbNKj85Ad1Q3mdKyK/s%2BV1rgizdUd5nSsiv7Plaa5cBtbzzz8ft912W/zoRz%2BKfv36RUREa2tr9O3bN4YNGxY///nPC45vbGyM4cOHR0TE8OHDY9euXcftnzhxYqfvv66uLmprawu2lZUNiLffbj6dcT5Qnz69Y9Cg8jhw4Ei0tbUnve1SyutcEfmdLa9zRZitO8rrXBH5ni0iijJXZWVF0tvrrFwG1vnnnx8tLS2xYsWKuPHGG6OpqSmWL18es2fPjj//8z%2BPFStWxHe/%2B92YO3dubN%2B%2BPR577LG47777IiJi9uzZUV9fH1OmTInRo0fHww8/HG%2B99VZMnjy50/dfVVV13MuBTU0H49ix4lwMbW3tRbvtUsrrXBH5nS2vc0WYrTvK61wR%2BZ0tT3PlMrAqKirigQceiK9//esxfvz4%2BMhHPhLTp0%2BP%2Bvr66NevX6xZsyaWLVsW3/nOd2LIkCHx1a9%2BNcaOHRsREePGjYs77rgj7rzzznjzzTdj2LBhsXr16hg8eHCJpwIAuotcBlbE73/yb82aNe%2B7r7q6Or7//e9/4PteffXVcfXVVxdraQBAzuXn2/UBALoIgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMTKSr0APpwxS54o9RI6beOXx5d6CQBwRngGCwAgMYEFAJCYwAIASOyMBNbOnTtj/vz5cemll8b48ePjK1/5Suzbty8iIl588cWYM2dOjBw5Mmpra2PdunUF77thw4aYPHly1NTUxKxZs%2BKFF144E0sGADhtRQ%2BslpaWWLBgQYwcOTL%2B67/%2BK/793/893nnnnbjtttti//798YUvfCFmzpwZW7dujWXLlsVdd90Vv/zlLyMiYsuWLbF06dK4%2B%2B67Y%2BvWrTFjxoy47rrr4siRI8VeNgDAaSt6YO3ZsycuuOCCqK%2Bvj379%2BkVlZWXU1dXF1q1bY9OmTTF48OCYO3dulJWVxbhx42L69Onx8MMPR0TEunXrYurUqTF69Ojo27dvfP7zn4/Kysp4/PHHi71sAIDTVvTA%2BtM//dN44IEHok%2BfPh3bnnzyybjwwgtj165dMWLEiILjhw0bFjt37oyIiMbGxhPuBwDois7oN7lnWRb33HNPbN68OZYsWRLNzc1RXl5ecEz//v3j8OHDEREn3Q8A0BWdsV80eujQobj11ltjx44d8b3vfS/OP//8KC8vj4MHDxYc19LSEhUVFRERUV5eHi0tLcftr6ysPFPLPi179%2B6Npqamgm1lZQOiqqoq6f306dO9fgi0rKxz631vru42X2fkdba8zhVhtu4or3NF5Hu2iHzNdUYCa/fu3bFw4cL44z/%2B41i/fn0MGTIkIiJGjBgRP//5zwuObWxsjOHDh0dExPDhw2PXrl3H7Z84ceKZWPZpW7t2baxatapgW319fTQ0NJRoRV1DZWXFKR0/aFD5yQ/qpvI6W17nijBbd5TXuSLyO1ue5ip6YO3fvz%2BuueaaGDt2bCxbtix69/7/dTp58uT4xje%2BEd/97ndj7ty5sX379njsscfivvvui4iI2bNnR319fUyZMiVGjx4dDz/8cLz11lsxefLkYi/7Q6mrq4va2tqCbWVlA%2BLtt5uT3k93K/3Ozt%2BnT%2B8YNKg8Dhw4Em1t7UVe1ZmV19nyOleE2bqjvM4Vke/ZIqIoc53qF/epFD2wHn300dizZ09s3Lgxnnii8P/Ne%2BGFF2LNmjWxbNmy%2BM53vhNDhgyJr371qzF27NiIiBg3blzccccdceedd8abb74Zw4YNi9WrV8fgwYOLvewPpaqq6riXA5uaDsaxY/m7GE7Fqc7f1tae23%2BzvM6W17kizNYd5XWuiPzOlqe5ih5Y8%2BfPj/nz53/g/urq6vj%2B97//gfuvvvrquPrqq4uxNACAouherzEBAHQDAgsAIDGBBQCQmMACAEhMYAEAJCawAAASO2P/VQ5AdzVmyRMnP6gL2fjl8aVeAvR4nsECAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiuQ6sffv2xeTJk2PLli2lXgoA0IPkNrC2b98edXV1sXv37lIvBQDoYXIZWBs2bIibbropbrjhhlIvBQDogXIZWJdffnk89dRTcdVVV5V6KQBAD1RW6gUUw9ChQ0t6/3v37o2mpqaCbWVlA6Kqqirp/fTp0736uKysc%2Bt9b67uNl9n5HW2vM4V0T1n6unXWl7nisj3bBH5miuXgVVqa9eujVWrVhVsq6%2Bvj4aGhhKtqGuorKw4peMHDSov0kpKL6%2Bz5XWu7sa19nt5nSsiv7PlaS6BVQR1dXVRW1tbsK2sbEC8/XZz0vvpbqXf2fn79OkdgwaVx4EDR6Ktrb3Iqzqz8jpbXueK6H7XWYRrLa9zReR7togoylyn%2BgVHKgKrCKqqqo57ObCp6WAcO5a/i%2BFUnOr8bW3tuf03y%2BtseZ2ru3Gt/V5e54rI72x5mqv7fWkGANDF5f4ZrF/96lelXgIA0MN4BgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiAgsAIDGBBQCQmMACAEhMYAEAJCawAAASE1gAAIkJLACAxAQWAEBiZaVeQB7t3bs3mpqaCraVlQ2IqqqqpPfTp0/36uOyss6t9725utt8nZHX2fI6V0T3nKmnX2t5nSsi37NF5GuuXlmWZaVeRN6sXLkyVq1aVbDt%2Buuvj0WLFiW9n71798batWujrq4uebyVUl7nisjvbHmdK8Js3VFe54rI72x5nCs/qdiF1NXVxaOPPlrwp66uLvn9NDU1xapVq457tqy7y%2BtcEfmdLa9zRZitO8rrXBH5nS2Pc3mJsAiqqqpyU%2BAAwKnzDBYAQGICCwAgsT533nnnnaVeBKevoqIiLr300qioqCj1UpLK61wR%2BZ0tr3NFmK07yutcEfmdLW9z%2BSlCAIDEvEQIAJCYwAIASExgAQAkJrAAABITWAAAiQksAIDE/Fc5wGnZt29f1NXVxde%2B9rW47LLLjtu/YMGC2L59e8G2w4cPR11dXfz93/99/O53v4vx48fHgAEDOvZXVlbG008/XfS1Q1eyc%2BfOWL58eezYsSP69u0b48ePj8WLF8eQIUMKjnNNdS8CCzhl27dvj8WLF8fu3bs/8JgHHnig4O3169fHqlWr4vrrr4%2BIiJdeeinOOeccH/zp0VpaWmLBggXxl3/5l3H//fdHc3Nz3HLLLXHbbbfFP/3TPxUc65rqXjpeIty3b19Mnjw5tmzZcsJ3WLBgQVRXV8fIkSM7/jzzzDNFX2hP05nz8bOf/SymT58eNTU1MWXKlNi8eXPB/tWrV8fEiROjpqYm5s2bFy%2B//HKxl80f6Mw5PNH11NbWFsuXL49PfvKTMXLkyLjuuuvi2Wefjfnz58ell14a48ePj6985Suxb9%2B%2BD7z9kz1GTseGDRvipptuihtuuKHT7/Pyyy/H0qVL45vf/GbHf4T%2B0ksvxUUXXfSh10PnvPbaa3H99dfH2LFj47LLLou//du/jVdffbXUy%2Boyfve738X5559fcC3W1tYW/X737NkTF1xwQdTX10e/fv2isrIy6urqYuvWrSd8v2JcU88991zMmTMnRo0aFePHj4%2BlS5dGS0vLad9esXX2c1yWZXHvvfdGbW1tjBo1KqZPnx5PPPFEx/6infssy7Jt27ZlV155ZTZixIjsv//7v7MTueyyy7ItW7ac8Bg%2BnM6cj9/%2B9rdZdXV19tRTT2Xvvvtu9uMf/zi7%2BOKLszfeeCPLsix79NFHswkTJmS//vWvs5aWluyuu%2B7Kpk6dmrW3t5/JUXqszl5TJ7qeVq5cmU2fPj3bs2dPdvDgwWzRokXZRRddlH3729/Ojh49mu3bty9buHBh9sUvfvF93/9kj5HTtXfv3uzdd9/Nsizr1MeMLMuyz33uc9nf/d3fFWxbsGBBNmfOnGzq1KnZZZddli1YsCDbtWvXh1obH2zGjBnZbbfdljU3N2eHDh3Kbr311mzatGmlXlaX8fTTT2eTJk0q9TKyLMuym2%2B%2BOZs3b94Jj0l9Tb311ltZdXV19oMf/CBra2vL3nzzzWzatGnZt7/97dOeo5hO5XPcQw89lNXW1maNjY1Ze3t79tOf/jSrrq7OXnzxxSzLinfue5/KV6Ovvvpq7N%2B/Pz7xiU98%2BLLjfXX2fGzYsCHGjBkTV155ZZSVlcVVV10Vl1xySaxduzYiIh555JH47Gc/G8OHD4%2BzzjorbrzxxtizZ89Jn6Hkw%2BvsOTzZ9bRu3bpYuHBh/NEf/VEMHDgwrrnmmmhtbY0ZM2Z06ivdkz1GTtfQoUOjrKzz312wbdu2ePHFFztexnjPoEGDYvTo0fEv//Iv8ZOf/CTOPffcmD9/fhw8ePBDrY/j7d%2B/Pz760Y/Gl770pRgwYEBUVFTE5z73ufj1r38d%2B/fvL/XyuoSu8IxqlmVxzz33xObNm2PJkiUfeFwxrqkhQ4bEs88%2BG7NmzYpevXrFO%2B%2B8E0ePHj3u%2B8C6ilP5HHfgwIGor6%2BP8847L3r16hW1tbVx3nnnxfPPPx8RxTv3vS%2B//PJ46qmn4qqrrjrpwS%2B99FJUVFTEDTfcEGPHjo1p06bF%2BvXrky%2BqJ%2Bvs%2BWhsbIwRI0YUbBs2bFjs3Lnzfff37ds3zj333I79FE9nz%2BGJrqeDBw/GG2%2B8UXAOR48eHYMHD47GxsaObU8%2B%2BWRceOGF73v7J3uMnClr166NKVOmxNChQwu2r1ixIm655ZYYMmRIDBw4MG699dZobm6Obdu2ndH19QRnn312PPjggx0vJUX8/rFzzjnnxNlnn13ClXUdL730Urzxxhsxbdq0GDt2bCxcuLDgWiu2Q4cORUNDQzz22GPxve99L84///wPPLZY19TAgQMjIuKKK66I6dOnx9ChQ2PWrFmnP1QRncrnuIaGhoI5fvOb38SuXbs6PnYW69z3PpWvRltbW6OmpiZuuOGG%2BM///M9YvHhxLFu2LDZu3PihF8LvdfZ8NDc3R3l5ecG2/v37x%2BHDhzu1n%2BLp7Dk80fXU3NwcEVHw00ARvz%2BHzc3NnfpKtys8Bo4dOxY//elPY8aMGQXbDx06FMuXL4/XX3%2B9Y1tbW1scO3Ys%2Bvfvf8bW11P927/9W6xZsya%2B9rWvlXopXUYpn1HdvXt3fOYzn4lDhw7F%2BvXrTxhXZ%2BKa2rRpUzzzzDPRu3fvaGhoOLVhzpDT/fj229/%2BNhYuXBgzZsyISy65JCKKd%2B5P6acIZ86cGTNnzux4%2B/LLL4%2BZM2fGxo0bY8qUKR9qIZya8vLy4775sKWlJSoqKjq1n9I70fX0yU9%2BMiIijhw5UvA%2BLS0tHR/0duzYccKvdLvCY%2BBXv/pVHD16NEaNGlWwfeDAgfHss8/G66%2B/HsuWLYvevXvH8uXL40/%2B5E9izJgxZ2x9PU1ra2vcdddd8fjjj8f9998fY8eOLfWSuowVK1YUvH3rrbfGD37wg9i2bVtMmjSpaPe7f//%2BuOaaa2Ls2LEd18KJnIlrqn///tG/f/%2B4%2BeabY86cObF///4u90zn6Xx8e/rpp2Px4sUxa9asuOWWWzq2F%2Bvcn9IvGl2/fv1xz1a1trbGWWedddoL4PSMGDEidu3aVbCtsbExhg8fHhERw4cPL9j/7rvvxiuvvHLcS0aUzomup7PPPjs%2B9rGPFTxN3dTUFO%2B8805861vf6tRXuid7jBTDyJEj40c/%2BlHH26%2B%2B%2BmqcffbZ7/sx4r777ov29va48sorY8KECdHU1BSrV6%2BOvn37Fm19Pdm%2Bffti3rx58T//8z%2Bxfv16cfUHSvmM6qOPPhp79uyJjRs3xujRowt%2Bki3izF1Tzz//fHz605%2BO1tbWjm2tra3Rt2/f454p6gpO9XPcvffeGzfeeGPcfvvtsXjx4ujVq1dEFPnc/%2BF3vJ/sJ4IeeuihbNy4cdmOHTuytra2bPPmzdnFF1%2Bcbd26Nfl333Pi89HY2JhVV1dnP/7xjzt%2BQqy6ujp7%2BeWXsyzLskceeSSbMGFC9r//%2B78dP2ExefLkrLW19UyO0OOd6Bye7Hq65557smnTpmW7d%2B/ODh48mNXX12cXXXRRtnjx4qytre2k932yxwg9R2tra/YXf/EX2bXXXpsdOXKk1MvpkmbMmJEtWrQoO3DgQHbo0KHs9ttvz6ZMmdJjPmYeOnQou%2BKKK7Kvf/3r2dGjR7PXXnstmz17dnbHHXeUemnv61Q%2Bx61ZsyYbPXp0tmPHjve9rWKd%2B5MGVk1NTfbDH/4wy7Isa29vz%2B69995s0qRJ2cUXX5xNnTo127hx44daAB/s/56PPzwXWZZlzzzzTDZjxoyspqYmmzp1avYf//EfHfva29uzBx98MKutrc1qamqyefPm%2BcRaAic6hye7nlpbW7NvfOMb2YQJE7JRo0ZlU6dOzUaMGJH92Z/9WVZTU1Pw5/1uP8tO/Bih53jyySezESNGZNXV1cc9dl5//fVSL69T/vqv/zq7/fbbi3b7r732WlZfX59deuml2ciRI7O/%2BZu/yV577bWi3V9XtGvXrmz%2B/PnZmDFjskmTJmX/8A//kB09erRj///9%2BFJKnf0c197eno0ePTr7xCc%2Bcdxj/x//8R%2BzLCveue%2BVZVn24Z4DAwDgD/nPngEAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBITGABACQmsAAAEhNYAACJCSwAgMQEFgBAYgILACAxgQUAkJjAAgBI7P8BxXs1I9X%2BkX8AAAAASUVORK5CYII%3D"/>
</div>
<div role="tabpanel" class="tab-pane col-md-12" id="common8885073346795181634">
| Value | Count | Frequency (%) | |
| 3 | 491 | 55.1% | |
| 1 | 216 | 24.2% | |
| 2 | 184 | 20.7% |
Minimum 5 values
| Value | Count | Frequency (%) | |
| 1 | 216 | 24.2% | |
| 2 | 184 | 20.7% | |
| 3 | 491 | 55.1% |
Maximum 5 values
| Value | Count | Frequency (%) | |
| 1 | 216 | 24.2% | |
| 2 | 184 | 20.7% | |
| 3 | 491 | 55.1% |
sex
Categorical
| Distinct count | 2 |
|---|---|
| Unique (%) | 0.2% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| male | |
|---|---|
| female | |
| Value | Count | Frequency (%) | |
| male | 577 | 64.8% | |
| female | 314 | 35.2% |
sibsp
Numeric
| Distinct count | 7 |
|---|---|
| Unique (%) | 0.8% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Infinite (%) | 0.0% |
| Infinite (n) | 0 |
</div>
<div class="col-sm-6">
<table class="stats ">
<tr>
<th>Mean</th>
<td>0.52301</td>
</tr>
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>Maximum</th>
<td>8</td>
</tr>
<tr class="alert">
<th>Zeros (%)</th>
<td>68.2%</td>
</tr>
</table>
</div>
</div>

</ul>
<div class="tab-content">
<div role="tabpanel" class="tab-pane active row" id="quantiles697864874961638462">
<div class="col-md-4 col-md-offset-1">
<p class="h4">Quantile statistics</p>
<table class="stats indent">
<tr>
<th>Minimum</th>
<td>0</td>
</tr>
<tr>
<th>5-th percentile</th>
<td>0</td>
</tr>
<tr>
<th>Q1</th>
<td>0</td>
</tr>
<tr>
<th>Median</th>
<td>0</td>
</tr>
<tr>
<th>Q3</th>
<td>1</td>
</tr>
<tr>
<th>95-th percentile</th>
<td>3</td>
</tr>
<tr>
<th>Maximum</th>
<td>8</td>
</tr>
<tr>
<th>Range</th>
<td>8</td>
</tr>
<tr>
<th>Interquartile range</th>
<td>1</td>
</tr>
</table>
</div>
<div class="col-md-4 col-md-offset-2">
<p class="h4">Descriptive statistics</p>
<table class="stats indent">
<tr>
<th>Standard deviation</th>
<td>1.1027</td>
</tr>
<tr>
<th>Coef of variation</th>
<td>2.1085</td>
</tr>
<tr>
<th>Kurtosis</th>
<td>17.88</td>
</tr>
<tr>
<th>Mean</th>
<td>0.52301</td>
</tr>
<tr>
<th>MAD</th>
<td>0.71378</td>
</tr>
<tr class="">
<th>Skewness</th>
<td>3.6954</td>
</tr>
<tr>
<th>Sum</th>
<td>466</td>
</tr>
<tr>
<th>Variance</th>
<td>1.216</td>
</tr>
<tr>
<th>Memory size</th>
<td>7.0 KiB</td>
</tr>
</table>
</div>
</div>
<div role="tabpanel" class="tab-pane col-md-8 col-md-offset-2" id="histogram697864874961638462">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAlgAAAGQCAYAAAByNR6YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAPYQAAD2EBqD%2BnaQAAADl0RVh0U29mdHdhcmUAbWF0cGxvdGxpYiB2ZXJzaW9uIDIuMS4xLCBodHRwOi8vbWF0cGxvdGxpYi5vcmcvAOZPmwAAIABJREFUeJzt3X10VPW97/FPkgkwCYkZhED1sk6UBMHAsimEhyL0GEyjQgB5MEdphR4rSiJpaImIBqFACBw81YaIUik3FdISzYEqCAhXKT4UIWAPVFbBhIOoKz1kgCSQJ8jT/cND7p1GxwC/yc5s3q%2B18kd%2Be8/s7ycTFp/Ze2YS0NLS0iIAAAAYE2j1AAAAAHZDwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhjmsHuB64XZfMH6fgYEB6tEjVOfO1ai5ucX4/VvFrrkk%2B2azay6JbP7Irrkk%2B2bzZa5evcKM3l97cQbLjwUGBiggIECBgQFWj2KUXXNJ9s1m11wS2fyRXXNJ9s1mx1wULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwzGH1AL5SWVmp5cuXa%2B/evWpublZ8fLwWL16syMhIHT58WMuWLVNpaalcLpdmz56tadOmtd52y5YtWrNmjdxut2699VYtXLhQcXFxFqb5ZkOf2Wn1CO22I2OU1SMAANAhbHsGa86cOaqtrdXu3bu1Z88eBQUFaeHChaqqqtKsWbM0adIkFRcXKzs7Wzk5OTpy5Igkaf/%2B/Vq6dKlWrFih4uJiTZgwQbNnz1ZdXZ3FiQAAgL%2BwZcH65JNPdPjwYa1YsULh4eHq3r27li5dqnnz5mnXrl2KiIjQ9OnT5XA4NHLkSCUnJ6ugoECS9Prrr2vcuHEaMmSIgoODNXPmTLlcLm3fvt3iVAAAwF/Y8hLhkSNHFB0drddee01/%2BMMfVFdXp9GjR2v%2B/PkqKSlR//79PfaPjo5WUVGRJKm0tFRTpkxps/3YsWPtPn55ebncbrfHmsMRosjIyKtM9PWCgvyrHzsc7Zv3ci5/y9ceds1m11wS2fyRXXNJ9s1mx1y2LFhVVVU6fvy4Bg0apC1btqi%2Bvl5PPvmk5s%2Bfr549e8rpdHrs361bN9XW1kqSampqvG5vj8LCQuXl5XmspaWlKT09/SoT2YPLFXpF%2B4eHO799Jz9l12x2zSWRzR/ZNZdk32x2ymXLgtWlSxdJ0jPPPKOuXbuqe/fuysjI0AMPPKDJkyervr7eY//6%2BnqFhn71n7/T6fza7S6Xq93HT0lJUUJCgseawxGiioqaq4nzjfyt6bc3f1BQoMLDnTp/vk5NTc0%2Bnqpj2TWbXXNJZPNHds0l2TebL3Nd6ZN7U2xZsKKjo9Xc3KyGhgZ17dpVktTc/NUDNnDgQP3%2B97/32L%2B0tFQxMTGSpJiYGJWUlLTZPmbMmHYfPzIyss3lQLf7ghob7fOP4Wpcaf6mpmbb/szsms2uuSSy%2BSO75pLsm81OufzrFEg7ff/731ffvn319NNPq6amRufOndPzzz%2Bvu%2B%2B%2BW%2BPHj9eZM2eUn5%2BvhoYGffTRR9q6dWvr666mTp2qrVu36qOPPlJDQ4Py8/N19uxZJSYmWpwKAAD4C1sWrODgYG3YsEFBQUFKSkpSUlKS%2BvTpo%2BXLl8vlcmn9%2BvXauXOnhg8frqysLGVlZWnEiBGSpJEjR2rRokVavHixhg0bprfeekuvvPKKIiIiLE4FAAD8hS0vEUpS79699fzzz3/ttsGDB2vTpk3feNuJEydq4sSJvhoNAADYnC3PYAEAAFiJggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGNYhBevs2bNKTU3V0KFDNXz4cGVnZ6uxsbF1%2B%2BHDhzVt2jTFxcUpISFBr7/%2BekeMBQAA4BMdUrAyMjIUEhKi999/X0VFRdq3b5/y8/MlSVVVVZo1a5YmTZqk4uJiZWdnKycnR0eOHOmI0QAAAIzzecE6deqUDhw4oMzMTDmdTvXt21epqakqKCiQJO3atUsRERGaPn26HA6HRo4cqeTk5NbtAAAA/sbhbePKlSs1efJkxcTEXPUBSkpKFBERod69e7eu9evXT2VlZTp//rxKSkrUv39/j9tER0erqKjoqo9ptfLycrndbo81hyNEkZGRRo8TFORfL6FzONo37%2BVc/pavPeyaza65JLL5I7vmkuybzY65vBasQ4cOKT8/X7GxsZoyZYrGjRun8PDwKzpATU2NnE6nx9rl72tra792e7du3VRbW3tFx%2BlMCgsLlZeX57GWlpam9PR0iybqHFyu0CvaPzzc%2Be07%2BSm7ZrNrLols/siuuST7ZrNTLq8F67XXXtPJkyf1xz/%2BUa%2B88opWrFihsWPHavLkyRo1apQCAgK%2B9QAhISGqq6vzWLv8fWhoqJxOpy5cuOCxvb6%2BXqGhV/afcWeSkpKihIQEjzWHI0QVFTVGj%2BNvTb%2B9%2BYOCAhUe7tT583Vqamr28VQdy67Z7JpLIps/smsuyb7ZfJnrSp/cm%2BK1YEnSLbfcorlz52ru3Lk6cOCAdu3apTlz5uiGG27Q5MmTlZKS4nH57x/FxMSosrJSZ86cUc%2BePSVJJ06cUJ8%2BfRQWFqb%2B/fvrww8/9LhNaWnpNV2WtFpkZGSby4Fu9wU1NtrnH8PVuNL8TU3Ntv2Z2TWbXXNJZPNHds0l2TebnXK1%2BxTIkSNHtGvXLu3atUuSFB8fr0OHDumHP/yh3nzzzW%2B8XVRUlIYMGaLly5erurpaX3zxhdasWaOpU6dKkhITE3XmzBnl5%2BeroaFBH330kbZu3aopU6ZcYzQAAABreD2D9fe//11vvPGG3njjDZ08eVJ33HGHnnjiCd13333q3r27JGn16tVavny5JkyY8I33k5ubqyVLlmjs2LEKDAzUpEmTlJqaKklyuVxav369srOzlZubqx49eigrK0sjRowwGBMAAKDjeC1YCQkJuvHGG5WcnKy8vDz169evzT633367oqKivB6kZ8%2Beys3N/cbtgwcP1qZNm9o3MQAAQCfntWCtXr1ad911l4KCglrXLl68qK5du7Z%2BP3bsWI0dO9Z3EwIAAPgZr6/BGjVqlBYsWKCXXnqpde2HP/yhsrKydOnSJZ8PBwAA4I%2B8FqycnBwdPnxY8fHxrWtZWVkqLi7W888/7/PhAAAA/JHXgvXOO%2B9o5cqVGjp0aOtaYmKisrOztW3bNp8PBwAA4I%2B8Fqza2lqFhYW1WXe5XG0%2BHBQAAABf8Vqw4uLitHbtWjU1NbWutbS06He/%2B50GDx7s8%2BEAAAD8kdd3Ef785z/Xj3/8Yx08eFCxsbEKCAjQ0aNHVVlZqfXr13fUjAAAAH7F6xmsQYMGadu2bRo/frwaGhrU3Nys8ePHa8eOHbrjjjs6akYAAAC/8q1/i/Dmm2/Wz3/%2B846YBQAAwBba/bcIAQAA0D4ULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBaudTp48qRkzZiguLk633XabYmNjtXnz5tbte/fuVXJysr773e/q3nvv1Z49eyycFgAAWImC1Q4NDQ16/PHHNXjwYO3fv1/Dhg1Tc3Ozzp07J0n67LPPNGfOHP3sZz/TwYMHNWfOHGVkZOj06dMWTw4AAKxAwWqH4uJilZeXKz09XWvXrtV3vvMdBQcHq6CgQJK0ZcsWDR06VHfffbccDofuu%2B8%2BxcfHq7Cw0OLJAQCAFRxWD%2BAPSkpKdMstt%2Bjjjz/WW2%2B9pf/4j//Q3r17deHCBUlSaWmp%2Bvfv37p/eXm5IiIiVFxcrKNHj0qSHI4QRUZGGp0rKMi/%2BrHD0b55L%2Bfyt3ztYddsds0lkc0f2TWXZN9sdsxFwWqHmpoa1dfX6%2Bmnn1Zubq5CQ0PVrVs3ud3u1u1Op7N1/8LCQm3dulWSNHnyZElSWlqa0tPTO374TsTlCr2i/cPDnd%2B%2Bk5%2Byaza75pLI5o/smkuybzY75aJgtUNISIhOnjypJ598UoMGDZIk1dfXKzT0q8LgdDpVX1/fun9KSopOnTql06dP66mnnpL01Rmsiooao3P5W9Nvb/6goECFhzt1/nydmpqafTxVx7JrNrvmksjmj%2ByaS7JvNl/mutIn96ZQsNrhhhtuUFBQkHJzc/Xiiy9Kki5cuKCuXbvqscce04ABA1ovBUpSZGSkKisrNWTIEMXGxkqS3O4Lamy0zz%2BGq3Gl%2BZuamm37M7NrNrvmksjmj%2ByaS7JvNjvl8q9TIBZJTk5W79699S//8i/68MMPtXHjRkVGRmrx4sVau3atJkyYoAMHDmj79u1qbGzU9u3bdeDAAU2cONHq0QEAgAUoWO3gcDi0fv16ffrppxo1apRmzZqlqqqq1u39%2BvXTiy%2B%2BqLVr1yo%2BPl5r1qzR6tWrdcstt1g4NQAAsAqXCNvpn/7pn/Tb3/72G7ePHj1ao0eP7sCJAABAZ8UZLAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYQ6rB4Cn8%2BfP64UXVmn//j%2BroaFRAwferieeyFBMzG1Wj2YbBQW/09q1L8rhCFZYWJgmTpysf/3XWVaPBQCwEc5gdTIrVy5VTU21Nm36o7Zvf0cDB8bqqad%2BYfVYtrFjxza9/HKexoy5S1u3vq2oqFv0%2B9%2B/qnff/T9WjwYAsBEKVifzy1/maMmSFQoLC1Ntba2qqy8oIsJl9Vi28eabWxQYGKhFi5YpNLS7/v3fV6u5uUWbN79m9WgAABvhEmEn43A45HA4tHbti9q4MV8hISH6t3/7tdVj2cbJk/%2Blfv1iFBwcLOmrn3dU1C0qLf3U4skAAHZCwfKB8vJyud1ujzWHI0SRkZHtvo9HHnlUjz76mIqKXtO8eXO0cWOhbr75f3nsExTkXycgHY72zXs5ly/y1dXVKiTE6TGL09lNdXV17Z7vWvgym5Xsmksimz%2Byay7JvtnsmIuC5QOFhYXKy8vzWEtLS1N6evoV3Evo/9zuMb311hs6eHCfBg2aaW5IC7hcoVe0f3i40/gMTqdTDQ2XPGZpbGxQaGjoFc93LXyRrTOway6JbP7Irrkk%2B2azUy4Klg%2BkpKQoISHBY83hCFFFRc233vbRR2fqwQd/pISEu1vX6usvyuHo1ub2/tb025Nf%2BipXeLhT58/Xqamp2egMt9zST59%2Bekxud5UcDocaGxtUWlqqAQMGtnu%2Ba%2BHLbFayay6JbP7Irrkk%2B2bzZa6OfPL8/6Ng%2BUBkZGSby4Fu9wU1Nn77L83AgbH6zW9eVv/%2BA9Wjx43asOF/69KlSxo5cnS7bt%2BZXen8TU3NxjMnJd2nTz45ogULntTixdlavPgZXbx4UUlJ4zr05%2BuLbJ2BXXNJZPNHds0l2TebnXJRsDqZxx%2Bfo8DAID322E/U2Nig2NjB%2BvWvX1J4eLjVo9nCxImTVV19QS%2B/nKfx4xNVX1%2Bnxx9/QhMm3G/1aAAAG6FgdTJdunTRE09k6IknMqwexZYCAgL0ox/N1I9%2BNNPqUQAANuZfL%2BIBAADwAxQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAyjYAEAABjm%2BLYd6urq9Omnn6qhoUEtLS0e2%2BLj4302GAAAgL/yWrD%2B9Kc/KTMzU9XV1W3KVUBAgP72t7/5dDgAAAB/5LVgPffccxo6dKh%2B9rOfKSwsrKNmAgAA8GteC9apU6f0wgsvKDo6uqPm6RDHjh3TypUrdfToUQUHB2vUqFF66qmn1KNHDx0%2BfFjLli1TaWmpXC6XZs%2BerWnTprXedsuWLVqzZo3cbrduvfVWLVy4UHFxcRam8R/3vvCh1SNckR0Zo6weAQDgp7y%2ByD0qKkrnzp3rqFk6RH19vX76058qLi5OH3zwgbZt26bKyko9/fTTqqqq0qxZszRp0iQVFxcrOztbOTk5OnLkiCRp//79Wrp0qVasWKHi4mJNmDBBs2fPVl1dncWpAABAZ%2BK1YGVmZmrp0qV699139dlnn6msrMzjyx%2BVlZVpwIABSktLU5cuXeRyuZSSkqLi4mLt2rVLERERmj59uhwOh0aOHKnk5GQVFBRIkl5//XWNGzdOQ4YMUXBwsGbOnCmXy6Xt27dbnAoAAHQmXi8Rzpo1S5KUmpqqgICA1vWWlha/fZH7rbfeqnXr1nmsvf3224qNjVVJSYn69%2B/vsS06OlpFRUWSpNLSUk2ZMqXN9mPHjvl2aAAA4Fe8FqxXX321o%2BawREtLi1544QXt2bNHGzdu1Kuvviqn0%2BmxT7du3VRbWytJqqmp8br9svLycrndbo81hyNEkZGRRucPCuJjzHzJ4TD/8738mNntsbNrLols/siuuST7ZrNjLq8Fa9iwYR01R4errq7WggULdPToUW3cuFG33XabnE6nLly44LFffX29QkNDJUlOp1P19fVttrtcLo%2B1wsJC5eXleaylpaUpPT3dB0ngKy5XqM/uOzzc%2Be07%2BSG75pLI5o/smkuybzY75frWDxq1o88//1yPPvqobrrpJhUVFalHjx6SpP79%2B%2BvDDz3f6VZaWqqYmBhJUkxMjEpKStpsHzNmjMdaSkqKEhISPNYcjhBVVNQYzWGnpt8ZmX68pK8es/Bwp86fr1NTU7Px%2B7eKXXNJZPNHds0l2TebL3P58smyN9ddwaqqqtKMGTM0YsQIZWdnKzDw/5WUxMRErVq1Svn5%2BZo%2BfboOHTqkrVu3as2aNZKkqVOnKi0tTffee6%2BGDBmigoICnT17VomJiR7HiIyMbHM50O2%2BoMZG%2B/xjuB748vFqamq25e%2BDXXNJZPNHds0l2TebnXJddwVr8%2BbNKisr044dO7Rz506PbX/5y1%2B0fv16ZWdnKzc3Vz169FBWVpZGjBghSRo5cqQWLVqkxYsX6/Tp04qOjtYrr7yiiIgIK6IAAIBOKqDlH/8GDnzC7b7w7TtdIYcjUInPvW/8fvEVX3zQqMMRKJcrVBUVNbZ5libZN5dENn9k11ySfbP5MlevXtb8JRpexAMAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWAAAAIZRsAAAAAxzeNuYkJCggICAb9z%2BzjvvGB8IAADA33ktWPfff79HwWpoaNCpU6f03nvvKSMjw%2BfDAQAA%2BCOvBWvOnDlfu75x40YdOnRIDz/8sE%2BGAgAA8GdX9Rqsu%2B66S3v37jU9CwAAgC1cVcE6cOCAunbtanoWAAAAW/B6ifAfLwG2tLSourpax48f5/IgAADAN/BasG666aY27yIMDg7WjBkzlJyc7NPBAAAA/JXXgrVixYqOmgMAAMA2vBas4uLidt9RfHz8NQ8DAABgB14L1syZM9XS0tL6ddnly4aX1wICAvS3v/3Nh2MCAAD4D68Fa/Xq1crJydH8%2BfM1YsQIBQcH6/Dhw1q8eLEeeugh3XXXXR01JwAAgN/w%2BjENK1eu1KJFi3T33Xere/fu6tq1q4YNG6YlS5Zo/fr1uvnmm1u/AAAA8BWvBau8vFzf%2Bc532qx3795dFRUVPhsKAADAn3ktWN/97nf1q1/9StXV1a1rlZWVWrVqlUaOHOnz4QAAAPyR19dgZWVlacaMGRozZoyioqIkSSdPnlSvXr306quvdsR8AAAAfsdrwerXr5%2B2b9%2BurVu36sSJE5Kkhx56SOPGjZPT6eyQAQEAAPyN14IlSeHh4Zo2bZq%2B/PJL9e3bV9JXn%2BYOAACAr%2Bf1NVgtLS167rnnFB8fr/Hjx%2Bu///u/NX/%2BfC1YsEANDQ0dNSMAAIBf8VqwNmzYoDfeeEOLFi1Sly5dJEl333233n33Xf3617/ukAGvxtmzZ5WamqqhQ4dq%2BPDhys7OVmNjY%2Bv2w4cPa9q0aYqLi1NCQoJef/11C6cFAAB247VgFRYW6tlnn9XkyZNbP739vvvuU3Z2tt56660OGfBqZGRkKCQkRO%2B//76Kioq0b98%2B5efnS5Kqqqo0a9YsTZo0ScXFxcrOzlZOTo6OHDli7dAAAMA2vBasL7/8UgMHDmyzftttt%2BnMmTM%2BG%2BpanDp1SgcOHFBmZqacTqf69u2r1NRUFRQUSJJ27dqliIgITZ8%2BXQ6HQyNHjlRycnLrdgAAgGvltWDdfPPNX3tmZ%2B/eva0veO9sSkpKFBERod69e7eu9evXT2VlZTp//rxKSkrUv39/j9tER0fr2LFjHT0qAACwKa/vInzkkUf0y1/%2BUqdPn1ZLS4v27dunTZs2acOGDVqwYEFHzXhFampq2nyExOXva2trv3Z7t27dVFtba2yG8vJyud1ujzWHI0SRkZHGjiFJQUFe%2BzGukcNh/ud7%2BTGz22Nn11wS2fyRXXNJ9s1mx1xeC9aUKVPU2Niol156SfX19Xr22Wd14403au7cuXrwwQc7asYrEhISorq6Oo%2B1y9%2BHhobK6XTqwoULHtvr6%2BsVGhpqbIbCwkLl5eV5rKWlpSk9Pd3YMeB7Lpe534l/FB5uz8%2BRs2suiWz%2ByK65JPtms1MurwXrzTff1D333KOUlBSdO3dOLS0tuvHGGztqtqsSExOjyspKnTlzRj179pQknThxQn369FFYWJj69%2B%2BvDz/80OM2paWliomJMTZDSkqKEhISPNYcjhBVVNQYO4Zkr6bfGZl%2BvKSvHrPwcKfOn69TU1Oz8fu3il1zSWTzR3bNJdk3my9z%2BfLJsjdeC9ayZcsUGxurG264QT169Oioma5JVFSUhgwZouXLl2vJkiWqqKjQmjVrNHXqVElSYmKiVq1apfz8fE2fPl2HDh3S1q1btWbNGmMzREZGtrkc6HZfUGOjff4xXA98%2BXg1NTXb8vfBrrkksvkju%2BaS7JvNTrm8ngKJiorS8ePHO2oWY3Jzc9XY2KixY8fqgQce0OjRo5WamipJcrlcWr9%2BvXbu3Knhw4crKytLWVlZGjFihMVTAwAAu/B6BismJkbz5s3TunXrFBUVpa5du3psz8nJ8elwV6tnz57Kzc39xu2DBw/Wpk2bOnAiAABwPfFasD7//HMNGTJEktq8Kw4AAABfz2vB2rBhQ0fNAQAAYBttXoOVk5Nj9DOhAAAArjdtCtarr77a5nOkHnnkEZWXl3fYUAAAAP6sTcFqaWlps9PHH3%2BsixcvdshAAAAA/o5PqgQAADCMggUAAGDY1xasgICAjp4DAADANr72YxqWLVvm8aGiDQ0NWrVqVZs/iNxZP2gUAADASm0KVnx8fJsPFY2Li1NFRYUqKio6bDAAAAB/1aZg8eGiAAAA14YXuQMAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAMAoWAACAYRQsAAAAwyhYAAAAhlGwAAAADKNgAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDCH1QMAndW9L3xo9QhXZEfGKKtHAAD8D85gAQAAGEbBAgAAMIyCBQAAYBgFCwAAwDBe5A4A32LoMzutHuGK8IYHwHoULMAm/OldjxQAAHbHJUIAAADDKFgAAACGUbAAAAAM4zVYAADYlD%2B9NvNg9j1Wj2AUBcuPffHF51aPAKAT8qf/VHnDA%2ByKS4R%2B7OTJ/7J6BAAA8DU4g%2BUD5eXlcrvdHmsOR4giIyONHqeurk5Sd6P3CXQEh8N/ntsFBfnhWWtoAAAIS0lEQVTPrP7IF78Llx8zOz52ds4m2SsXBcsHCgsLlZeX57H2xBNPaM6cOUaP43BIDdvma/fu3a3l7fjx45owYYIOHjyosLAwo8frKOXl5SosLFRKSorxUmo1u2azay7pq2wz%2BpTYNpsdH7fy8nL97nfrbJdLuvJs/vK6pvLycq1evdpWj5l9qmInkpKSos2bN3t8paSkGD/ODTfcoPr6epWUlLSunThxQn369PHbciVJbrdbeXl5bc4C2oFds9k1l0Q2f2TXXJJ9s9kxF2ewfCAyMrJDGvhNN90kSVq/fr3uuOMOVVRUaM2aNZo6darPjw0AAL4ZBcsGmpqaNHbsWAUGBmrSpElKTU21eiQAAK5rFCwbyMzMVGxsrNVjAACA/xG0ePHixVYPgasXGhqqYcOGKTQ01OpRjLJrLsm%2B2eyaSyKbP7JrLsm%2B2eyWK6ClpaXF6iEAAADshHcRAgAAGEbBAgAAMIyCBQAAYBgFCwAAwDAKFgAAgGEULAAAAMMoWOiUzp07p8TERO3fv79d%2Bx87dkw/%2BclPNGzYMI0aNUpPPvmkzp075%2BMpgc5t%2B/btuv322xUXF9f6lZmZafVYgIejR49q%2BvTpGjp0qO68804tW7ZMly5dsnqsa0bBQqdz6NAhpaSk6PPPP2/X/vX19frpT3%2BquLg4ffDBB9q2bZsqKyv19NNP%2B3hSoHP761//qokTJ%2Bovf/lL69eqVausHgto1dzcrMcee0xJSUk6cOCAioqK9MEHH%2BiVV16xerRrRsHyU2fPnlVqaqqGDh2q4cOHKzs7W42NjVaPdc22bNmiefPmae7cue2%2BTVlZmQYMGKC0tDR16dJFLpdLKSkpKi4u9uGk%2BCb79u3TtGnT9L3vfU%2BjRo3S0qVLVV9fb/VY16W//vWvGjRokNVjGFdZWaknn3xSw4cPV3x8vFJTU1VeXm71WD7z5ptvepyFjIuL06BBg2zx2FZVVcntdqu5uVmXP/c8MDBQTqfT4smuHQXLT2VkZCgkJETvv/%2B%2BioqKtG/fPuXn51s91jW78847tXv3bt13333tvs2tt96qdevWKSgoqHXt7bff5u8zWuDcuXN67LHH9OCDD%2BrgwYPasmWLDhw4oN/85jdWj3bdaW5u1tGjR/WnP/1Jd911l8aMGaOFCxeqqqrK6tGu2Zw5c1RbW6vdu3drz549CgoK0sKFC60ey2cmTJjgcRZy586dioiIUHZ2ttWjXTOXy6WZM2dq5cqVGjx4sH7wgx8oKipKM2fOtHq0a0bB8kOnTp3SgQMHlJmZKafTqb59%2Byo1NVUFBQVWj3bNevXqJYfj6v8GeUtLi55//nnt2bNHzzzzjMHJ0B49evTQn//8Z02ePFkBAQGqrKzUxYsX1aNHD6tHu%2B6cO3dOt99%2Bu5KSkrR9%2B3Zt2rRJn332md%2B/BuuTTz7R4cOHtWLFCoWHh6t79%2B5aunSp5s2bZ/VoHaKlpUWZmZn653/%2BZ02cONHqca5Zc3OzunXrpoULF%2Bo///M/tW3bNp04cUK5ublWj3bNKFh%2BqKSkRBEREerdu3frWr9%2B/VRWVqbz589bOJm1qqurlZ6erq1bt2rjxo267bbbrB7putS9e3dJ0g9%2B8AMlJyerV69emjx5ssVTXX969uypgoICTZ06VU6nUzfddJMyMzP13nvvqbq62urxrtqRI0cUHR2t1157TYmJibrzzju1cuVK9erVy%2BrROsQbb7yh0tJSPfXUU1aPYsTu3bv19ttv66GHHlKXLl0UExOjtLQ0/eEPf7B6tGtGwfJDNTU1ba5PX/6%2BtrbWipEs9/nnn2vKlCmqrq5WUVER5aoT2LVrl9577z0FBgYqPT3d6nGuO8eOHdNzzz3X%2BroWSbp06ZICAwPVpUsXCye7NlVVVTp%2B/Lg%2B%2B%2BwzbdmyRX/84x91%2BvRpzZ8/3%2BrRfK65uVkvvfSSHn/88dYnMv7u73//e5t3DDocDgUHB1s0kTkULD8UEhKiuro6j7XL34eGhloxkqWqqqo0Y8YMfe9739Nvf/tbLkd1Et26dVPv3r2VmZmp999/3xav/fEnERERKigo0Lp169TY2KiysjKtWrVK999/v18XrMuzP/PMM%2Brevbt69uypjIwM7d27VzU1NRZP51v79%2B9XeXm5pk6davUoxtx5551yu916%2BeWX1dTUpC%2B%2B%2BEIvvfSSkpOTrR7tmlGw/FBMTIwqKyt15syZ1rUTJ06oT58%2BCgsLs3Aya2zevFllZWXasWOHhgwZ4vFOG3Ssjz/%2BWPfcc4/HM9JLly4pODjYFu8K8id9%2BvTR2rVr9c4772jYsGGaMmWKBg8erGeffdbq0a5JdHS0mpub1dDQ0LrW3NwsSR5n6%2Bzo7bffVmJiokJCQqwexZjo6GitXbtW7777roYPH66HH35YCQkJV/RO8s4qoMXuv5E29dBDD6lPnz5asmSJKioqNHv2bCUlJWnOnDlWj4brWE1NjcaNG6ekpCT94he/kNvtVkZGhmJjY7V48WKrx4MNNDQ0aNy4cRowYIBycnJ08eJFzZ07V2FhYcrLy7N6PJ9KTk7Www8/rGnTplk9CtqBM1h%2BKjc3V42NjRo7dqweeOABjR49WqmpqVaPhetcaGio1q1bp5KSEo0aNUo//vGP9f3vf58PfYUxwcHB2rBhg4KCgpSUlKSkpCT16dNHy5cvt3o0n/vyyy8VGRlp9RhoJ85gAQAAGMYZLAAAAMMoWAAAAIZRsAAAAAyjYAEAABhGwQIAADCMggUAAGAYBQsAAMAwChYAAIBhFCwAAADDKFgAAACGUbAAAAAMo2ABAAAYRsECAAAwjIIFAABgGAULAADAsP8L2AGUkQZISEIAAAAASUVORK5CYII%3D"/>
</div>
<div role="tabpanel" class="tab-pane col-md-12" id="common697864874961638462">
| Value | Count | Frequency (%) | |
| 0 | 608 | 68.2% | |
| 1 | 209 | 23.5% | |
| 2 | 28 | 3.1% | |
| 4 | 18 | 2.0% | |
| 3 | 16 | 1.8% | |
| 8 | 7 | 0.8% | |
| 5 | 5 | 0.6% |
Minimum 5 values
| Value | Count | Frequency (%) | |
| 0 | 608 | 68.2% | |
| 1 | 209 | 23.5% | |
| 2 | 28 | 3.1% | |
| 3 | 16 | 1.8% | |
| 4 | 18 | 2.0% |
Maximum 5 values
| Value | Count | Frequency (%) | |
| 2 | 28 | 3.1% | |
| 3 | 16 | 1.8% | |
| 4 | 18 | 2.0% | |
| 5 | 5 | 0.6% | |
| 8 | 7 | 0.8% |
survived
Boolean
| Distinct count | 2 |
|---|---|
| Unique (%) | 0.2% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| Mean | 0.38384 |
|---|
| 0 | |
|---|---|
| 1 | |
| Value | Count | Frequency (%) | |
| 0 | 549 | 61.6% | |
| 1 | 342 | 38.4% |
who
Categorical
| Distinct count | 3 |
|---|---|
| Unique (%) | 0.3% |
| Missing (%) | 0.0% |
| Missing (n) | 0 |
| man | |
|---|---|
| woman | |
| child | 83 |
| Value | Count | Frequency (%) | |
| man | 537 | 60.3% | |
| woman | 271 | 30.4% | |
| child | 83 | 9.3% |
Correlations


Sample
Facets is a library from Google that looks very good. It has similar functionality to pandas_profiling as well as some powerful visualization. Installation is more complex so we won’t use it now but it is worth considering.
https://github.com/pair-code/facets
Handling Data that Exceeds Your System’s RAM
Pandas is an in-memory system. The use of NumPy means it uses memory very efficiently but you are still limited by the RAM you have available. If your data is too large, there are several options available, including:
- process the data sequentially (may not be possible but see here for an interesting approach)
- partition the data into chunks and process those separately
- partition the data into chunks and use multiple computers configured as a cluster with
ipyparallel(https://ipyparallel.readthedocs.io/en/latest/) - use a DataFrame-like library that handles larger datasets, like Dask DataFrames (http://dask.pydata.org/en/latest/dataframe.html)
- use a tool like Apache Drill which can SQL queries against files on disk in formats like CSV
- putting the data in a database and operating on a subset in Pandas using a SELECT statement.
These are all out of scope of this document but we will briefly elaborate on the last two. Python comes standard with an implementation of Sqlite, in the package sqlite3. Pandas supports reading a DataFrame from the result of running a query against a Sqlite database. Here’s a very simple example of how that may look:
import sqlite3 as lite
with lite.connect('mydata.db') as con:
query = 'select * from sales limit 100'
df = pd.read_sql(query, con)
You can read more about Sqlite here: https://sqlite.org/quickstart.html.
Dask supports chunked dataframes that support most of the functionality of Pandas. The key additional parameter is blocksize which specifies the maximum size of a chunk of data to read into memory at one time. In addition, Dask methods are lazily evaluated; you must explicitly call a .compute() method to kick off the calculation. Here is a simple example: assume we have multiple CSV files containing temperature measurements. We could compute the mean temperature with something like:
import dask.dataframe as dd
df = dd.read_csv('temp*.csv', blocksize=25e6) # Use 25MB chunks
df.temperature.mean().compute()
Adding Interactivity with ipywidgets
ipywidgets is an extension package for Jupyter that allows output cells to include interactive HTML elements. To install, you will need to run a command to enable the extension from a terminal and then restart Jupyter. First, install the package; the code below shows the right way to do this from within the notebook:
!conda install -c conda-forge --prefix {sys.prefix} --yes ipywidgets
Solving environment: done
# All requested packages already installed.
Now you need to run this command from your terminal, kill and restart JupyterLab, then return here.
jupyter labextension install @jupyter-widgets/jupyterlab-manager
(You can run it from within JupyterLab but you will still need a restart before the widgets will work).
We will look at a simple example using the interact function from ipywidgets. You call this giving it a function as the first argument, followed by zero or more additional arguments that can be tuples, lists or dictionaries. These arguments will each become interactive controls like sliders and drop-downs, and any change in their values will cause the function to be called again with the new values as arguments.
See http://ipywidgets.readthedocs.io/en/stable/examples/Using%20Interact.html for more info on creating other types of controls when using interact.
from ipywidgets import interact
import pandas as pd
df = pd.DataFrame([[2, 1], [4, 4], [1, 2], [3, 6]], index=['a', 'b', 'c', 'd'], columns=['s1', 's2'])
def plot_graph(kind, col):
what = df if col == 'all' else df[col]
what.plot(kind=kind)
interact(plot_graph, kind=['line', 'bar'], col=['all', 's1', 's2'])
interactive(children=(Dropdown(description='kind', options=('line', 'bar'), value='line'), Dropdown(descriptio…
<function __main__.plot_graph>
Some Useful Packages and Resources
openpyxlallows you to create and work directly with Excel spreadsheetsfakercan create fake data like names, addresses, credit card numbers, and social security numbersnumbaincludes a@jitdecorator that can speed up the execution of many functions; useful when crunching data outside of Pandas (it won’t speed up Pandas code)moviepyallows you to edit video frame-by-frame (or even create video)- ray is a new package that lets you leverage your GPU to speed up pandas code
- qgrid is a Jupyter extension that adds interactive sorting, filtering and editing of DataFrames
Video tutorials on Pandas: http://www.dataschool.io/easier-data-analysis-with-pandas/
Jake VanderPlas’ excellent Python Data Science Handbook: https://jakevdp.github.io/PythonDataScienceHandbook/
Tom Augspurger has a great multi-part series on Pandas aimed at intermediate to advanced users.
Example: Loading JSON into a DataFrame and Expanding Complex Fields
In this example we’ll see how we can load some structured data and process it into a flat table form better suited to machine learning.
# Let's get some data; top stories from lobste.rs; populate a DataFrame with the JSON
stories = pd.read_json('https://lobste.rs/hottest.json')
stories.head()
| comment_count | comments_url | created_at | description | downvotes | score | short_id | short_id_url | submitter_user | tags | title | upvotes | url | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | https://lobste.rs/s/9fkwad/it_s_impossible_pro... | 2018-04-28 20:52:33 | 0 | 12 | 9fkwad | https://lobste.rs/s/9fkwad | {'username': 'apg', 'created_at': '2013-12-11T... | [privacy, security] | It’s Impossible to Prove Your Laptop Hasn’t Be... | 12 | https://theintercept.com/2018/04/28/computer-m... | |
| 1 | 0 | https://lobste.rs/s/iwvkly/unfixed_google_inbo... | 2018-04-28 07:03:40 | 0 | 33 | iwvkly | https://lobste.rs/s/iwvkly | {'username': 'eligrey', 'created_at': '2017-12... | [security, show] | Unfixed Google Inbox recipient spoofing vulner... | 33 | https://eligrey.com/blog/google-inbox-spoofing... | |
| 2 | 1 | https://lobste.rs/s/xjsf2r/chrome_is_showing_t... | 2018-04-29 02:13:21 | 0 | 6 | xjsf2r | https://lobste.rs/s/xjsf2r | {'username': 'stephenr', 'created_at': '2015-0... | [browsers, mobile, web] | Chrome is showing third party external links o... | 6 | https://twitter.com/backlon/status/99004255788... | |
| 3 | 4 | https://lobste.rs/s/js0ine/nethack_devteam_is_... | 2018-04-28 14:34:02 | <p>Interestingly, this will be the final relea... | 0 | 13 | js0ine | https://lobste.rs/s/js0ine | {'username': 'intercal', 'created_at': '2016-1... | [c, games] | The NetHack DevTeam is happy to announce the r... | 13 | https://groups.google.com/forum/#!topic/rec.ga... |
| 4 | 0 | https://lobste.rs/s/9ac8ha/how_get_core_dump_f... | 2018-04-28 22:35:08 | 0 | 7 | 9ac8ha | https://lobste.rs/s/9ac8ha | {'username': 'calvin', 'created_at': '2014-07-... | [debugging] | How to get a core dump for a segfault on Linux | 7 | https://jvns.ca/blog/2018/04/28/debugging-a-se... |
# Use the "short_id' field as the index
stories = stories.set_index('short_id')
# Show the first few rows
stories.head()
| comment_count | comments_url | created_at | description | downvotes | score | short_id_url | submitter_user | tags | title | upvotes | url | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| short_id | ||||||||||||
| 9fkwad | 2 | https://lobste.rs/s/9fkwad/it_s_impossible_pro... | 2018-04-28 20:52:33 | 0 | 12 | https://lobste.rs/s/9fkwad | {'username': 'apg', 'created_at': '2013-12-11T... | [privacy, security] | It’s Impossible to Prove Your Laptop Hasn’t Be... | 12 | https://theintercept.com/2018/04/28/computer-m... | |
| iwvkly | 0 | https://lobste.rs/s/iwvkly/unfixed_google_inbo... | 2018-04-28 07:03:40 | 0 | 33 | https://lobste.rs/s/iwvkly | {'username': 'eligrey', 'created_at': '2017-12... | [security, show] | Unfixed Google Inbox recipient spoofing vulner... | 33 | https://eligrey.com/blog/google-inbox-spoofing... | |
| xjsf2r | 1 | https://lobste.rs/s/xjsf2r/chrome_is_showing_t... | 2018-04-29 02:13:21 | 0 | 6 | https://lobste.rs/s/xjsf2r | {'username': 'stephenr', 'created_at': '2015-0... | [browsers, mobile, web] | Chrome is showing third party external links o... | 6 | https://twitter.com/backlon/status/99004255788... | |
| js0ine | 4 | https://lobste.rs/s/js0ine/nethack_devteam_is_... | 2018-04-28 14:34:02 | <p>Interestingly, this will be the final relea... | 0 | 13 | https://lobste.rs/s/js0ine | {'username': 'intercal', 'created_at': '2016-1... | [c, games] | The NetHack DevTeam is happy to announce the r... | 13 | https://groups.google.com/forum/#!topic/rec.ga... |
| 9ac8ha | 0 | https://lobste.rs/s/9ac8ha/how_get_core_dump_f... | 2018-04-28 22:35:08 | 0 | 7 | https://lobste.rs/s/9ac8ha | {'username': 'calvin', 'created_at': '2014-07-... | [debugging] | How to get a core dump for a segfault on Linux | 7 | https://jvns.ca/blog/2018/04/28/debugging-a-se... |
# Take a look at the submitter_user field; it is a dictionary itself.
stories.submitter_user[0]
{'about': 'Interested in programming languages, distributed systems and security (not very good at any of them). Currently: Metrics and operations at Heroku.\r\n\r\nPreviously: founder of [hack and tell](http://hackandtell.org): an informal, monthlish show and tell for hackers in NYC. Occasional SoCal surfer.\r\n\r\nElsewhere:\r\n\r\n* [homepage](http://apgwoz.com)\r\n* [blog](http://sigusr2.net)\r\n* [fediverse](https://bsd.network/@apg)\r\n\r\nIt probably goes without saying, but opinions are my own.',
'avatar_url': '/avatars/apg-100.png',
'created_at': '2013-12-11T11:00:03.000-06:00',
'github_username': 'apg',
'is_admin': False,
'is_moderator': False,
'karma': 3808,
'twitter_username': 'apgwoz',
'username': 'apg'}
# We want to expand these fields into our dataframe. First expand into its own dataframe.
user_df = stories.submitter_user.apply(pd.Series)
user_df.head()
| about | avatar_url | created_at | github_username | is_admin | is_moderator | karma | twitter_username | username | |
|---|---|---|---|---|---|---|---|---|---|
| short_id | |||||||||
| 9fkwad | Interested in programming languages, distribut... | /avatars/apg-100.png | 2013-12-11T11:00:03.000-06:00 | apg | False | False | 3808 | apgwoz | apg |
| iwvkly | I'm [Eli Grey](https://eligrey.com). | /avatars/eligrey-100.png | 2017-12-23T20:12:34.000-06:00 | eligrey | False | False | 33 | sephr | eligrey |
| xjsf2r | Ops/infrastructure and web app development.\r\... | /avatars/stephenr-100.png | 2015-04-22T19:29:06.000-05:00 | NaN | False | False | 497 | NaN | stephenr |
| js0ine | I like programming, and programming languages ... | /avatars/intercal-100.png | 2016-11-11T08:55:13.000-06:00 | NaN | False | False | 284 | NaN | intercal |
| 9ac8ha | Soon we will all have special names... names d... | /avatars/calvin-100.png | 2014-07-01T06:47:13.000-05:00 | NattyNarwhal | False | False | 25997 | NaN | calvin |
# We should make sure there are no collisions in column names.
set(user_df.columns).intersection(stories.columns)
{'created_at'}
# We can rename the column to avoid the clash
user_df = user_df.rename(columns={'created_at': 'user_created_at'})
# Now combine them, dropping the original compound column that we are expanding.
stories = pd.concat([stories.drop(['submitter_user'], axis=1), user_df], axis=1)
stories.head()
| comment_count | comments_url | created_at | description | downvotes | score | short_id_url | tags | title | upvotes | url | about | avatar_url | user_created_at | github_username | is_admin | is_moderator | karma | twitter_username | username | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| short_id | ||||||||||||||||||||
| 9fkwad | 2 | https://lobste.rs/s/9fkwad/it_s_impossible_pro... | 2018-04-28 20:52:33 | 0 | 12 | https://lobste.rs/s/9fkwad | [privacy, security] | It’s Impossible to Prove Your Laptop Hasn’t Be... | 12 | https://theintercept.com/2018/04/28/computer-m... | Interested in programming languages, distribut... | /avatars/apg-100.png | 2013-12-11T11:00:03.000-06:00 | apg | False | False | 3808 | apgwoz | apg | |
| iwvkly | 0 | https://lobste.rs/s/iwvkly/unfixed_google_inbo... | 2018-04-28 07:03:40 | 0 | 33 | https://lobste.rs/s/iwvkly | [security, show] | Unfixed Google Inbox recipient spoofing vulner... | 33 | https://eligrey.com/blog/google-inbox-spoofing... | I'm [Eli Grey](https://eligrey.com). | /avatars/eligrey-100.png | 2017-12-23T20:12:34.000-06:00 | eligrey | False | False | 33 | sephr | eligrey | |
| xjsf2r | 1 | https://lobste.rs/s/xjsf2r/chrome_is_showing_t... | 2018-04-29 02:13:21 | 0 | 6 | https://lobste.rs/s/xjsf2r | [browsers, mobile, web] | Chrome is showing third party external links o... | 6 | https://twitter.com/backlon/status/99004255788... | Ops/infrastructure and web app development.\r\... | /avatars/stephenr-100.png | 2015-04-22T19:29:06.000-05:00 | NaN | False | False | 497 | NaN | stephenr | |
| js0ine | 4 | https://lobste.rs/s/js0ine/nethack_devteam_is_... | 2018-04-28 14:34:02 | <p>Interestingly, this will be the final relea... | 0 | 13 | https://lobste.rs/s/js0ine | [c, games] | The NetHack DevTeam is happy to announce the r... | 13 | https://groups.google.com/forum/#!topic/rec.ga... | I like programming, and programming languages ... | /avatars/intercal-100.png | 2016-11-11T08:55:13.000-06:00 | NaN | False | False | 284 | NaN | intercal |
| 9ac8ha | 0 | https://lobste.rs/s/9ac8ha/how_get_core_dump_f... | 2018-04-28 22:35:08 | 0 | 7 | https://lobste.rs/s/9ac8ha | [debugging] | How to get a core dump for a segfault on Linux | 7 | https://jvns.ca/blog/2018/04/28/debugging-a-se... | Soon we will all have special names... names d... | /avatars/calvin-100.png | 2014-07-01T06:47:13.000-05:00 | NattyNarwhal | False | False | 25997 | NaN | calvin |
# The tags field is another compound field.
stories.tags.head()
short_id
9fkwad [privacy, security]
iwvkly [security, show]
xjsf2r [browsers, mobile, web]
js0ine [c, games]
9ac8ha [debugging]
Name: tags, dtype: object
# Make a new dataframe with the tag lists expanded into columns of Series.
tag_df = stories.tags.apply(pd.Series)
tag_df.head()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| short_id | ||||
| 9fkwad | privacy | security | NaN | NaN |
| iwvkly | security | show | NaN | NaN |
| xjsf2r | browsers | mobile | web | NaN |
| js0ine | c | games | NaN | NaN |
| 9ac8ha | debugging | NaN | NaN | NaN |
# Pivot the DataFrame
tag_df = tag_df.stack()
tag_df
short_id
9fkwad 0 privacy
1 security
iwvkly 0 security
1 show
xjsf2r 0 browsers
1 mobile
2 web
js0ine 0 c
1 games
9ac8ha 0 debugging
sgvyct 0 android
1 linux
2 networking
bq7zc0 0 hardware
yiwxq1 0 javascript
fe8sly 0 philosophy
1 programming
yvogbz 0 math
1 visualization
vqaslr 0 release
1 show
cy0nbk 0 programming
1 scaling
12pegw 0 go
1 release
mtpakk 0 clojure
k6evtc 0 culture
1 haskell
jgyhfp 0 compilers
1 lisp
2 pdf
3 python
sv7ntm 0 hardware
1 video
gs56zl 0 art
1 graphics
2 release
pwibis 0 compilers
1 elixir
2 erlang
zvdbag 0 practices
hnwahp 0 ai
1 programming
su5y1j 0 networking
1 philosophy
2 visualization
dhevll 0 programming
1 rust
f0zug5 0 mobile
1 security
w6i96s 0 crypto
1 cryptocurrencies
2 security
dtype: object
# Expand into a 1-hot encoding
tag_df = pd.get_dummies(tag_df)
tag_df.head()
| ai | android | art | browsers | c | clojure | compilers | crypto | cryptocurrencies | culture | ... | programming | python | release | rust | scaling | security | show | video | visualization | web | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| short_id | ||||||||||||||||||||||
| 9fkwad | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| iwvkly | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | |
| xjsf2r | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 38 columns
# Merge multiple rows
tag_df = tag_df.sum(level=0)
tag_df.head()
| ai | android | art | browsers | c | clojure | compilers | crypto | cryptocurrencies | culture | ... | programming | python | release | rust | scaling | security | show | video | visualization | web | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| short_id | |||||||||||||||||||||
| 9fkwad | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| iwvkly | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| xjsf2r | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| js0ine | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9ac8ha | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 38 columns
# And add back to the original dataframe
stories = pd.concat([stories.drop('tags', axis=1), tag_df], axis=1)
stories.head()
| comment_count | comments_url | created_at | description | downvotes | score | short_id_url | title | upvotes | url | ... | programming | python | release | rust | scaling | security | show | video | visualization | web | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| short_id | |||||||||||||||||||||
| 9fkwad | 2 | https://lobste.rs/s/9fkwad/it_s_impossible_pro... | 2018-04-28 20:52:33 | 0 | 12 | https://lobste.rs/s/9fkwad | It’s Impossible to Prove Your Laptop Hasn’t Be... | 12 | https://theintercept.com/2018/04/28/computer-m... | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | |
| iwvkly | 0 | https://lobste.rs/s/iwvkly/unfixed_google_inbo... | 2018-04-28 07:03:40 | 0 | 33 | https://lobste.rs/s/iwvkly | Unfixed Google Inbox recipient spoofing vulner... | 33 | https://eligrey.com/blog/google-inbox-spoofing... | ... | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | |
| xjsf2r | 1 | https://lobste.rs/s/xjsf2r/chrome_is_showing_t... | 2018-04-29 02:13:21 | 0 | 6 | https://lobste.rs/s/xjsf2r | Chrome is showing third party external links o... | 6 | https://twitter.com/backlon/status/99004255788... | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| js0ine | 4 | https://lobste.rs/s/js0ine/nethack_devteam_is_... | 2018-04-28 14:34:02 | <p>Interestingly, this will be the final relea... | 0 | 13 | https://lobste.rs/s/js0ine | The NetHack DevTeam is happy to announce the r... | 13 | https://groups.google.com/forum/#!topic/rec.ga... | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9ac8ha | 0 | https://lobste.rs/s/9ac8ha/how_get_core_dump_f... | 2018-04-28 22:35:08 | 0 | 7 | https://lobste.rs/s/9ac8ha | How to get a core dump for a segfault on Linux | 7 | https://jvns.ca/blog/2018/04/28/debugging-a-se... | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 57 columns
Further Reading
The definitive Pandas book is the one by Wes McKinney, original author of Pandas. I also recommend Jake Vanderplas’s book, and the one by Matt Harrison. The links below are affiliate links where I may earn a small commission:



